
안녕하세요. 언제나 휴일입니다.
이번에는 Scikit-Learn을 이용한 KMean 군집화를 알아볼게요.
머신러닝에서 Label(정답 or 기대값)을 제공하여 학습하는 것을 지도학습이라고 불러요.
그리고 Label을 제공하지 않고 학습하는 것을 비지도학습이라고 부릅니다.
앞에서 지도학습 중에 분류와 회귀를 살펴보았죠.
이번에 다룰 KMean 군집화는 비지도학습입니다.
데이터를 K개의 군집으로 나누는 것이죠.
머신러닝 분류에서는 특정 데이터가 어떤 분류에 속하는지 학습 데이터로 제공하였습니다. 이 때의 분류 값이 Label이었어요.
머신러닝 군집화에서는 특정 데이터까 어떤 군집에 속하는지 학습 데이터로 제공하지 않습니다. 오히려 머신러닝 과정에서 정해지는 것이죠.
그리고 군집화를 위한 여러 가지 모델 중에 대표적인 것이 KMean 군집화입니다.
KMean 군집화는 다음의 과정을 통해 군집화를 진행합니다.
1. K 개의 중심점 설정
2. 모든 데이터를 K개의 중심정과의 거리 계산
가장 가까운 중심점을 선택하여 군집 결정
3. 군집별로 중심점 계산
* 2~3을 반복(군집이 바뀌는 데이터가 발생하지 않을 때까지 반복-반복할 횟수를 정할 수도 있음)


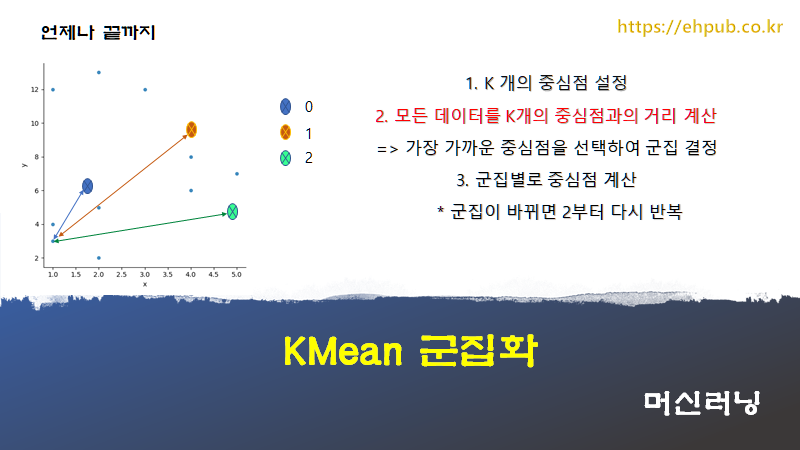




이와 같은 과정을 통해 더 이상 군집이 바뀌지 않을 때까지 반복
다음은 scikit-learn을 이용한 KMean 군집화 코드로 표현한 예제입니다.
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.DataFrame(columns=['x','y'])
df.loc[0] = [1,4]
df.loc[1] = [1,3]
df.loc[2] = [2,5]
df.loc[3] = [2,2]
df.loc[4] = [1,12]
df.loc[5] = [2,13]
df.loc[6] = [3,12]
df.loc[7] = [4,6]
df.loc[8] = [4,8]
df.loc[9] = [5,7]
print(df)
sns.lmplot('x','y',data=df,fit_reg=False,scatter_kws={"s":20})
plt.show()
data_points = df.values
kmeans = KMeans(n_clusters=3).fit(data_points)
df['label']=kmeans.labels_
print(df)
sns.lmplot('x','y',data=df,fit_reg=False,scatter_kws={"s":20},hue='label')
plt.show()