
안녕하세요. 언제나휴일입니다.
선형 회귀는 KNN(K-Nearest Neighbor)과 함께 가장 기초적인 머신 러닝 모델입니다.
KNN 회귀 모델에서는 주어진 독립 변수와 거리가 가장 k 개의 가까운 이웃의 평균 값으로 예측하는 모델이었습니다.
선형 회귀는 독립 변수와 종속 변수 사이의 선형 관계를 모델링합니다.
학습 결과로 선형 예측 함수를 얻을 수 있습니다.
여기에서는 선형 회귀가 무엇인지 간단히 알아볼 거예요.
그리고 선형 예측 함수를 구하기 위한 방법 중에 경사 하강법을 알아볼 거예요.
마지막으로 사이킷 런의 선형 회귀 모델을 사용해 볼게요.
선형 회귀란? 경사 하강법을 이용한 선형 회귀 사이킷 런의 선형 회귀 모델
1. 선형 회귀란?
선형 회귀는 하나 이상의 독립 변수(x)가 종속 변수(y)에 선형 상관 관계를 모델링하는 것을 말합니다.
선형 관계 수식은 다음처럼 표현할 수 있을 거예요.
y = ax + b
만약 독립 변수가 여러 개 있다면 다음처럼 표현할 수 있어요.
y = a1x1 + a2x2 +a3x3 + … + b
머신 러닝에서는 독립 변수(x)가 종속 변수(y)에 영향을 미치는 정도를 w(가중치, weight)이라고 부릅니다.
주어진 독립 변수 외에 종속 변수에 영향을 미치는 나머지를 b(편향, bias)이라고 합니다.
우리가 수학에서 배웠던 기울기를 가중치인 것이죠. x절편이 편향인 것이고요.
y = wx + b
y = w1x1 + w2x2 +w3x3 + … + b
머신 러닝에서는 학습을 통해 독립 변수와 종속 변수를 가장 잘 표현할 수 있는 선형 예측 함수를 만들어 냅니다.
선형 예측 함수는 학습을 통해 오차가 제일 작은 가중치와 편향을 통해 값을 예측할 수 있는 함수를 말합니다. 이러한 함수를 개발자가 만드는 것이 아니라 머신 러닝 모델이 학습을 통해 만드는 것이죠.
코드를 통해 간단한 예를 들어 볼게요.
다음과 같은 데이터가 있다고 가정할게요.
import matplotlib.pyplot as plt ex_xs = [[2],[4],[7],[1],[9],[6]] ex_ys = [8,11,24,5,30,20] plt.plot(ex_xs[:],ex_ys,'o',label='example data') plt.legend() plt.show()
다음은 독립 변수와 종속 변수의 상관 관계를 예측한 세 개의 직선을 도표로 나타낸 것입니다.
plt.plot(ex_xs[:],ex_ys,'o',label='example data') plt.plot([0,10],[0*2+2,10*2+2] ,label='y=2x+2') plt.plot([0,10],[0*3+2,10*3+2] ,label='y=3x+2') plt.plot([0,10],[0*4+2,10*4+2] ,label='y=4x+2') plt.legend() plt.show()
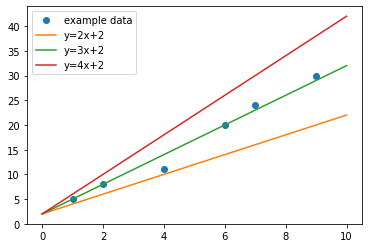
이 중에 예제 데이터를 가장 잘 표현한 예측 함수는 “y = 3x + 2“라고 할 수 있을 거예요.
선형 회귀 모델은 주어진 학습 데이터를 통해 가장 잘 표현할 수 있는 선형 예측 함수를 찾는 모델입니다.
2. 경사 하강법을 이용한 선형 회귀
선형 예측 함수를 찾는 방법 중에 대표적인 것이 경사 하강법입니다.
경사 하강법은 미분값의 절대값이 낮은 쪽(0에 근접한 쪽)으로 이동시키는 과정을 반복하여 경사가 낮은 지점(미분값이 0인 지점)을 찾는 방법입니다.
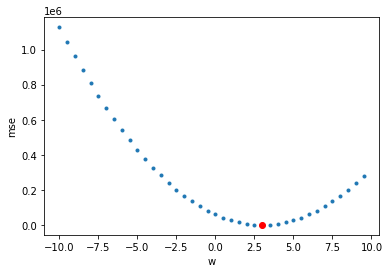
어떻게 경사 하강법을 이용하여 선형 예측 함수를 구할 수 있는지 알아봅시다.
선형 예측 함수는 데이터를 잘 표현할 수 있는 선형 함수라고 말했어요.
잘 표현하였는지를 판단하기 위해 실제 데이터와 예측 데이터 사이의 차이를 비교해야겠죠.
이를 손실 함수라고 말합니다.
많이 사용하는 손실 함수는 절대값과 제곱을 취하는 것입니다.
mean absolute error : 절대값(실제 데이터 – 예측 데이터)
mean squared error : (실제 데이터 – 예측 데이터)2
여기에서는 mse(평균 제곱 오차, mean squared error) 함수를 사용하여 예를 들게요.
다음은 가중치를 -10 ~10 사이를 0.5씩 변화를 주면서 mse 값을 구하는 코드입니다.
*편향은 2라고 구했다고 가정할게요.
import numpy as np b=2 mses=[] wpl = np.arange(-10,10,0.5) for wp in wpl: yp = wp*np.array(ex_xs)+b mses.append(np.mean(sum((yp-ex_ys)**2)))
이를 도표로 나타내면 다음과 같습니다.
mse = mean(실제 데이터 – 예측 데이터)2
예측 함수의 w, b를 포함하면 다음과 같습니다.
mse = mean(y – wx+b)2
편향 w로 편미분하면 다음과 같습니다.
mse/dw = 2mean(y – wx+b)×x
편향 b로 편미분하면 다음과 같습니다.
mse/db = 2mean(y – wx+b)
파이썬 코드로 작성하면 다음처럼 구현할 수 있어요.
def mse(yp, y): return np.mean(sum((yp-y)**2)) def gradient(ys,xs,w,b): yp = w*xs + b error = ys - yp wd = -(2/len(xs))*sum(xs * error) bd = -(2/len(xs))*sum(error) return wd,bd
경사 하강법은 초기 가중치와 편향을 설정(보통 -1~1 사이의 값으로 설정)한 후에 경사(미분값)를 빼주는 것을 반복하여 밑바닥(경사가 0인)을 찾는 과정입니다.
이 때 경사를 그대로 빼주지 않고 특정 비율(learning rate, 학습 비율)을 곱한 만큼 빼 줍니다.
*epochs은 몇 번 반복 수행할 것인지를 나타냅니다.
def gradient_descent(xs,ys,lr=0.001,epochs=100):
if isinstance(xs,list): #xs 형식이 리스트일 때
xs = np.array(xs).reshape(-1) #numpy 배열로 변경하고 1차원으로 구조 변경
wbhl=[] #학습 과정에서의 가중치와 편향을 보관하기 위함
wp = np.random.uniform(-1,1) #초기 가중치
bp = np.random.uniform(-1,1) #초기 편향
amse = 0 #이후 mse를 기억하기 위한 변수
for epoch in range(epochs):
bmse = amse #이전 mse를 설정
wd,bd = gradient(ys,xs,wp,bp)#경사를 구함
yp = wp*xs+bp #예측
amse = mse(yp,ys) #이후 mse 계산
wp = wp - (wd*lr) #가중치를 경사*lr만큼 빼기
bp = bp - (bd*lr) #편향을 경사*lr만큼 빼기
wbhl.append([wp,bp]) #가중치와 편향을 보관
if np.abs(bmse - amse)<0.001: #이전 mse와 이후 mse의 차이가 작을 때
break #반복문 탈출
return wp, bp, wbhl #가중치, 편향, 히스토리 반환
이제 경사하강법을 적용해 봅시다.
wp, bd, wbhl = gradient_descent(ex_xs,ex_ys)
for epoch, (wp, bd) in enumerate(wbhl):
print(f'epoch:{epoch} w:{wp} b:{bp}')
실행 결과
*랜덤 요소가 있기 때문에 실행 결과는 다를 수 있어요.
epoch:0 w:0.4890096975743311 b:0.22711430884302414 epoch:1 w:0.6723632438589257 b:0.22711430884302414 epoch:2 w:0.8440053329186537 b:0.22711430884302414 epoch:3 w:1.0046836771298142 b:0.22711430884302414 ...중략... epoch:97 w:3.3494036093717896 b:0.22711430884302414 epoch:98 w:3.3496276087898087 b:0.22711430884302414 epoch:99 w:3.3498321773103537 b:0.22711430884302414
학습 과정을 도표로 나타내 봅시다.
독립 변수와 종속 변수를 1차원 numpy 배열로 바꾸기로 할게요.
xs = np.array(ex_xs) xs = xs[:,0] ys = np.array(ex_ys)
이제 학습 단계마다 도표로 나타냅시다.
min_val = min(min(xs),min(ys))
max_val = max(max(xs),max(ys))
for epoch,wb in enumerate(wbhl):
plt.figure(figsize=(6,6))
sx = min_val
sy = sx*wb[0] + wb[1]
ex = max_val
ey = ex*wb[0] + wb[1]
plt.plot(xs,ys,'.',label='actual')
plt.plot([sx,ex],[sy,ey],'-r',label=f"epoch:{epoch} y = x*{wb[0]:.2f}+{wb[1]:.2f}")
plt.axvline(x=0,color='black')
plt.axhline(y=0,color='black')
plt.xlim(min_val,max_val)
plt.ylim(min_val,max_val)
plt.legend()
plt.show()
다음은 출력한 도표의 일부입니다.
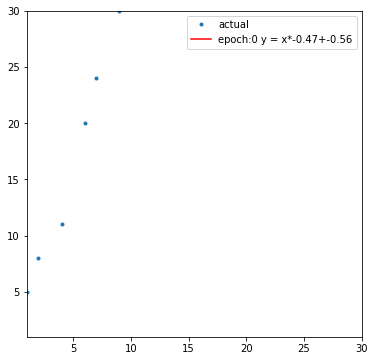
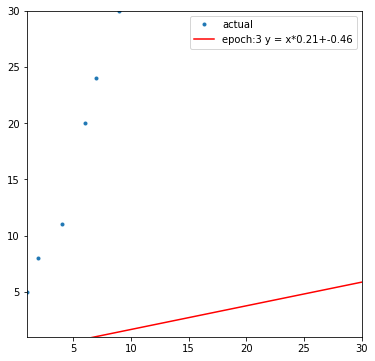
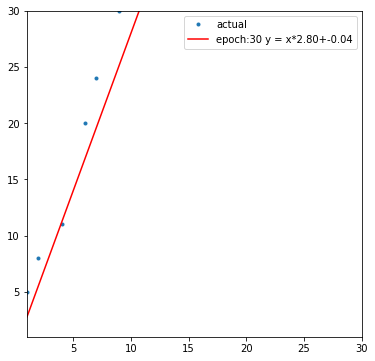
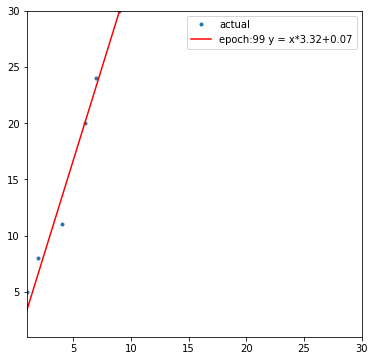
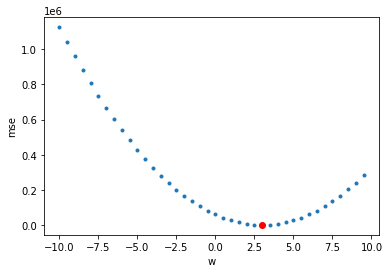
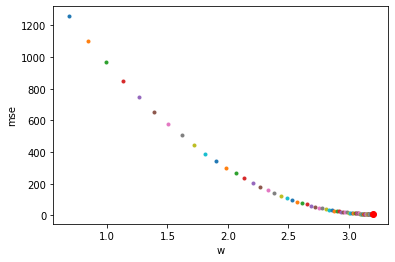
다음은 학습 과정에서 경사 하강하는 모습입니다.
y축은 mse, x축은 w
min_index = -1 #최솟값이 있는 인덱스
min_mse = np.inf #최솟값
for epoch, (wp, bd) in enumerate(wbhl):
yp = wp*xs+bd
mse_val = mse(yp,ys)
if min_mse > mse_val: #기존 최솟값이 더 클 때
min_mse = mse_val #최솟값을 변경
min_index = epoch #최솟값 인덱스를 변경
plt.plot(wp,mse_val,'.')
plt.plot(wbhl[epoch][0],mse_val,'ro') #최소값은 빨간색 원으로 표시
plt.xlabel('w')
plt.ylabel('mse')
plt.show()
3. 사이킷 런의 선형 회귀 모델
사이킷 런의 가장 기초적인 선형 회귀 모델로 LinearRegression을 제공합니다.
학습(fit) 후에 가중치는 멤버 coef_, 편향은 멤버 intercept_를 이용하면 확인할 수 있습니다.
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
lr_model.fit(ex_xs,ex_ys)
print(f'w:{lr_model.coef_}, b:{lr_model.intercept_}')
결과
w:[3.1886121], b:0.9217081850533795
이제 종속 변수(y)값을 모르는 독립 변수 목록을 전달하여 예측할 수 있습니다.
predict_values = lr_model.predict([[12],[45],[23]]) print(predict_values)
출력 결과
[ 39.18505338 144.40925267 74.25978648]
이상으로 경사 하강법을 이용한 선형 회귀를 알아보았습니다.