
이제 힙 정렬 알고리즘을 살펴보기로 해요.
힙 정렬은 완전 이진 트리의 한 종류인 힙 트리를 이용하여 정렬하는 알고리즘입니다. 먼저 힙 트리가 무엇인지 살펴본 후에 힙 정렬 알고리즘을 알아보고 분석 및 구현해 봅시다.
힙 트리는 부모의 값이 자식의 값보다 큰 값을 보장하는 최대 힙과 작은 값을 보장하는 최소 힙이 있습니다. 최대 힙으로 표현한 힙 트리의 루트에는 가장 큰 값을 갖고 최소 힙으로 표현하면 가장 작은 값을 갖습니다.
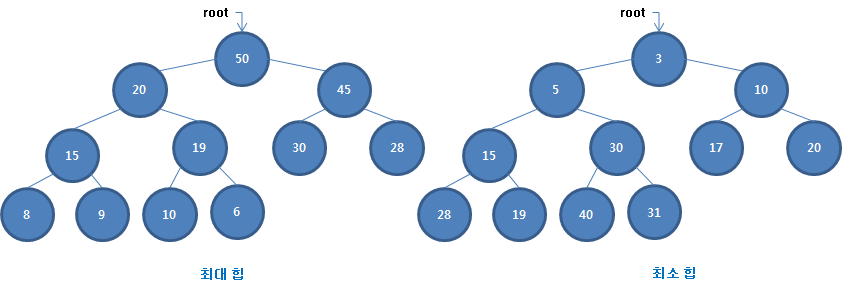
힙 트리처럼 완전 이진 트리는 배열로 많이 표현합니다. 완전 이진 트리가 아닌 이진 트리도 배열로 표현할 수 있지만 트리의 높이가 높아지고 한 쪽으로 기울어질 수록 비어있는 공간이 많아져서 메모리 효율이 떨어집니다. 하지만 완전 이진 트리는 마지막 자료가 있는 공간까지 모두 사용하여 빈 공간이 생기지 않습니다.
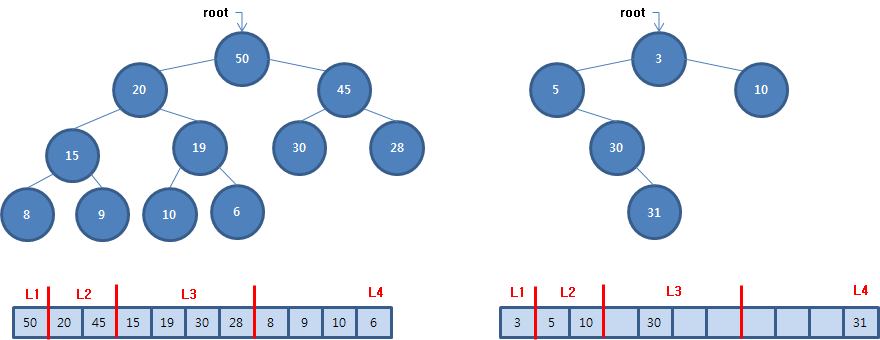
배열로 이진 트리를 표현할 때는 인덱스 0은 루트, 1은 루트의 왼쪽 자식, 2는 루트의 오른쪽 자식처럼 완전 이진 트리에서 노드를 매다는 순서와 배열의 인덱스가 같습니다. 완전 이진 트리에 자료를 매달때 배열로 표현하면 보관한 마지막 자료 뒤에 보관합니다. 하지만 완전 이진 트리가 아니면 계산에 의해 매달 위치를 찾아야 하며 비어있는 곳이 생깁니다.
매달 위치를 계산하는 것은 어렵지 않지만 비어있는 곳이 생기는 것은 이진 트리의 기울어짐이 커질 수록 비어있는 곳은 기하급수적으로 늘어날 수가 있어서 메모리 낭비가 심해질 수 있습니다. 이러한 이유로 완전 이진 트리가 아닐 때는 노드를 이용하여 구현하는 것이 효과적입니다. 반면 완전 이진 트리는 배열로 표현해도 메모리 낭비가 없기 때문에 노드를 이용하여 구현하지 않고 배열로 표현할 때가 많습니다.
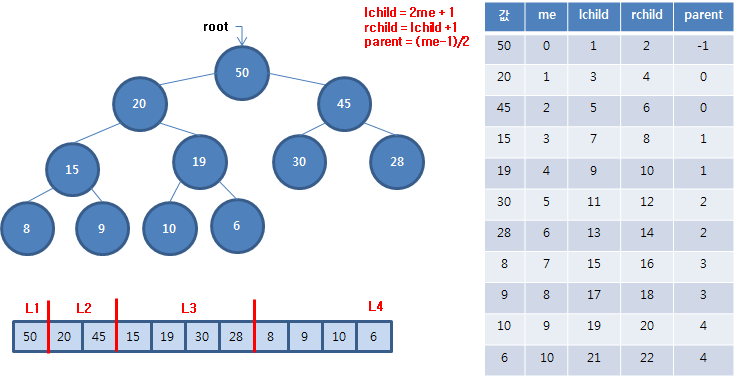
완전 이진 트리를 표현하다보면 목적에 따라 부모나 자식의 위치를 알아야 할 때가 있습니다. 노드로 표현한다면 링크로 부모나 자식의 위치를 알 수 있지만 배열로 표현할 때는 계산에 의해 알아내야 합니다.
나의 인덱스가 me 일 때 왼쪽 자식의 인덱스는 2me+1 위치에 있습니다. 루트 노드의 인덱스가 0이고 왼쪽 자식의 인덱스는 1입니다. 그리고 인덱스 1인 노드의 자식 노드는 2X1+1 = 3 이므로 인덱스 3입니다. 위 그림을 보면 루트 노드의 왼쪽 자식 노드는 갖고 있는 자료 값이 20입니다. 아래 그림을 보면 자료 20은 인덱스 1에 보관함을 알 수 있습니다.
나의 왼쪽 자식의 인덱스가 lchild일 때 오른쪽 자식의 인덱스는 lchild + 1 입니다. 루트 노드의 인덱스가 0이고 왼쪽 자식의 인덱스가 1이므로 오른쪽 자식의 인덱스는 2입니다. 위 그림을 보면 루트 노드의 오른쪽 자식 노드는 갖고 있는 자료 값이 45입니다. 아래 그림을 보면 자료 45는 인덱스 2에 있습니다.
이를 정리하면 위 그림의 오른쪽 표처럼 나의 인덱스 값에 따라 왼쪽 자식, 오른쪽 자식, 부모의 인덱스를 알 수 있습니다.
이에 관한 식은 다음과 같습니다.
lchild = 2me +1
rchild = lchid +1
parent = (me-1)/2
매크로 함수로 표현하면 다음처럼 표현할 수 있겠죠.
#define LCHILD(me) (2*me +1) #define RCHILD(me) (LCHILD(me)+1) #define PARENT(me) ((me-1)/2)