
프라이버시 보호 모델
- k-익명성(k-anonymity)
특정인임을 추론할 수 있는지 여부를 검토하여 일정 확률수준 이상 비식별되도록 하는 것을 말합니다.
같은 값이 K 개 이상 존재하도록 하면 특정 개인을 식별할 확률은 1/k입니다.
공개 데이터에 대한 연결공격 취약점을 방어하기 위해 사용합니다.
k-익명성의 취약점으로 동질성 공격과 배경지식에 의한 공격을 들 수 있습니다.
동질성 공격: 레코드를 범주화하더라도 일부 정보들이 모두 같은 값을 가질 수 있어서 이를 이용하는 공격입니다.
배경 지식에 의한 공격: 주어진 데이터 이외의 배경 지식을 통해 공격 대상의 민감한 정보를 알아내는 공격입니다.
- l-다양성(l-diversity)
특정이 추론이 안된다고 해도 민감한 정보의 다양성을 높여 추론 가능성을 낮추는 기법입니다.
각 레코드는 최소 l(엘)개 이상의 다양성을 가지도록 하여 동질성 또는 배경지식 등에 의한 추론을 막을 수 있습니다.
l-다양성의 취약점으로 쏠림 공격, 유사성 공격이 있습니다.
쏠림 공격: 정보가 특정한 값에 쏠려 있어 l-다양성 모델이 프라이버시를 보호하지 못할 수 있습니다.
예) •임의의 ‘동질 집합’이 99개의 ‘위암 양성’ 레코드와 1개의 ‘위암 음성’ 레코드로 구성되어 있다 가정 •공격자는 공격 대상이 99%의 확률로 ‘위암 양성’이라는 것을 알 수 있음
유사성 공격: 비식별 조치된 레코드의 정보가 서로 비슷하다면 ℓ-다양성 모델을 통해 비식별 된다 할지라도 프라이 버시가 노출될 수 있습니다.
예) 아래의 표를 보면 레코드 1,2,3이 속한 동질 집합의 병명이 서로 다르지만 ‘위’에 관련된 것을 알아낼 수 있습니다.
다른 민감한 정보인 급여에 대해서도 공격 대상이 다른 사람에 비해 상대적으로 낮은 것을 쉽게 알 수 있습니다.

- t-근접성 (t-closeness)
l-다양성 뿐만 아니라, 민감한 정보의 분포를 낮추어 추론 가능성을 더욱 낮추는 기법입니다.
전체 데이터 집합의 정보 분포와 특정 정보의 분포 차이를 t이하로 하여 추론을 방지합니다.
프라이버시 보호 모델 예
- k-익명성(k-anonymity)
본 자료는 개인정보 비식별 조치 가이드라인(국무조정실, 행정자치부, 방송통신위원회, 금융위원회, 미래창조과학부,보건복지부)의 내용을 참고하였습니다.
<표1>과 <표2>를 연결하면 김민준 (13053, 28, 남)은 전립선염을 걸렸던 것을 알 수 있다.


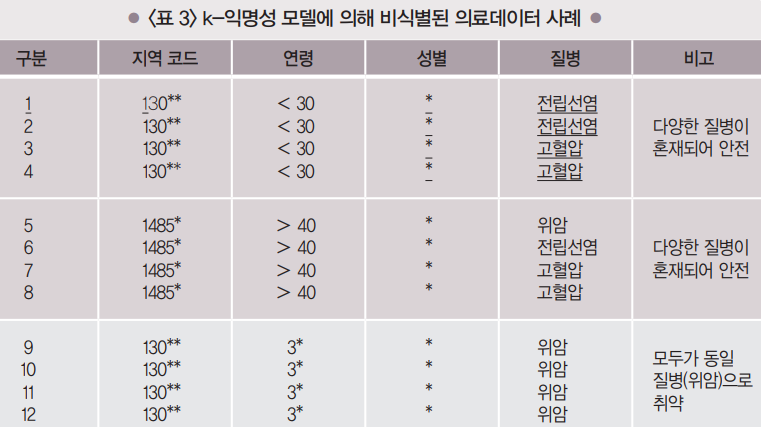
<표3>은 지역코드, 연령, 질병 등을 같은 속성을 갖도록 비식별 처리를 하여 어떤 레코드가 공격 대상인지 알아낼 수 없게 하였습니다.
- l-다양성(l-diversity)
<표 3>에서 레코드 9~12의 질병정보는 모두 ‘위암’이므로 k-익명성 모델이 적용되었음에 도 불구하고 그 질병정보가 직접적으로 노출되고 있는 상태입니다.
<표 2>와 <표 3>에서 공격자가 ‘이지민’의 질병을 알아내려고 하면 정보의 결합(13068, 29, 여)에 따라 ‘이지민’은 <표 3>의 1~4 레코드 중 하나이며 질병은 전립선염 또는 고혈압임을 알 수 있습니다.
이 때, ‘여자는 전립선염에 걸릴 수 없다’라는 배경 지식에 의해 공격 대상 ‘이지민’의 질병은 고혈압으로 쉽게 추론 가능합니다.
<표 4> 서로 다른 정보를 3개 이상 가지고 있어 어느 정도 방어력을 갖습니다.

- t-근접성(t-closeness)

<표 5>의 1,2,3은 모두 ‘위’에 관한 질병들이고 급여도 다른 집단에 비해 낮다는 것을 알 수 있습니다.
이러한 특징으로 쏠림 공격이나 유사성 공격을 받을 수 있습니다.
이를 해결하기 위해 정보의 분포’를 조정하여 정보가 특정 값으로 쏠리거나 유사한 값들이 뭉치는 경우를 방지합니다.
<표 6>에서 t-근접성 모델에 따라 레코드 1, 3, 8은 하나의 동질 집합입니다.
레코드 1, 3, 8의 급여의 분포는 (30 ~ 90)으로 전체적인 급여의 분포(30 ~ 110)와 큰 차이가 나지 않습니다.
레코드 1, 3, 8의 질병 분포는 위궤양, 만성위염, 폐렴으로 병명이 서로 다르고 질병이 ‘위’와 관련된 것 이외에 ‘폐’와 관계된 것도 있어 특정 부위의 질병임을 유추하기 어렵습니다.

마이데이터
개인이 자신의 정보에 대하여 정보주체가 접근하거 저장하고, 활용하는 등의 능동적인 의사결정을 하는 서비스입니다.
정보 주체가 개인정보를 본인 또는 제3자에게 전송 요구할 수 있도록 함으로써 신용평가, 자산관리, 건강관리 등 데이터 기반 서비스에 주도적으로 활용할 수 있습니다.
자신의 정보를 보호받기 위해 자신에 관한 정보를 자율적으로 결정하고 관리하는 개인정보 자기결정권을 갖습니다.