
안녕하세요. 언제나 휴일에 언휴예요.
강의 개요
이번 강의는 CSV 파일에 내용을 읽어서 원하는 컬럼을 추출하는 방법을 알아볼게요.
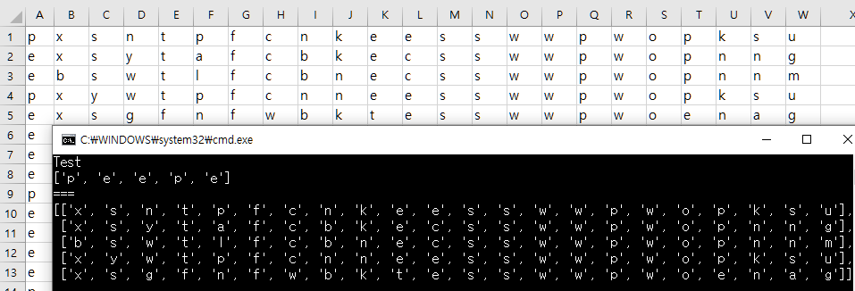
위 그림은 독버섯에 관한 파일입니다.
맨 첫번째 컬럼의 값이 ‘p’인 것은 독버섯, ‘e’인 것은 식용 버섯입니다.
나머지 컬럼은 독버섯인지 식용 버섯인지 판별하는데 영향을 주는 데이터들입니다.
이와 같은 데이터는 기계 학습(Merchine Leraning, ML)에 사용하죠.
이처럼 CSV 파일에 있는 내용을 기계 학습에 사용하려면 위 그림처럼 원하는 컬럼을 추출하여야 합니다.
== 다루는 내용 ==
원하는 컬럼만 추출하기
모든 행에 반복 작업할 때 - iterrows 메서드 사용
특정 컬럼 추출할 때 - loc[추추할 컬럼(들)]
data의 알파벳을 수로 바꾸기
ord 함수
원하는 컬럼만 추출하기
실습에 사용할 파일 다운로드(mushrooms.csv)
이번 강의는 pandas를 이용할 거예요.
pandas를 import하고 csv 파일을 읽어옵니다.
import pandas as pd
mr = pd.read_csv("mushrooms.csv",header=None)
첫 번째 column 값들과 나머지 column 값들을 보관할 변수를 선언할게요.
label=[] #독 버섯인지 판별한 데이터 ('p'는 독버섯, 'e'는 식용 버섯)
data=[] #독 버섯인지 판별에 필요한 데이터
pandas의 DataFrame의 각 행을 반복적인 작업을 할 때는 iterrows 메서드를 호출하여 사용합니다.
iterrows메서드를 호출하면 row 인덱스와 row 데이터를 반환합니다.
다음은 DataFrame의 행 번호와 행의 데이터를 반복해서 출력하는 예제입니다.
(*설명을 위한 코드입니다. 확인 후에 주석 처리하세요. *)
for row_index, row in mr.iterrows():
print(row_index)
print(row)
우리는 각 행의 0번째 column을 추출하여 label에 추가할 거예요.
이 때 DataFrame에 loc[컬럼 인덱스]를 사용합니다.
for row_index, row in mr.iterrows():
#print(row_index)
#print(row)
label.append(row.loc[0]) #row.ix[0] 더 이상 지원하지 않는다.
많은 책과 사이트에는 ix를 사용하라고 나오지만 더 이상 지원하지 않습니다.
이제 나머지 컬럼 데이터를 하나의 리스트로 만들어 data에 추가할게요.
이 때도 loc을 사용할게요. 컬럼 인덱스 1에서 나머지 전체를 사용할 것이므로 loc[1:]처럼 표현합니다.
for v in row.loc[1:]:
other_data.append(ord(v)-ord('a')+1)
data.append(other_data)
중간 확인
현재까지 작성한 것에 label과 data를 출력하는 코드를 추가하세요.
#파일 위치: https://ehpub.co.kr/files
#파일 이름: mushrooms.csv
import pandas as pd
mr = pd.read_csv("mushrooms.csv",header=None)
print(type(mr))
label=[] #독 버섯인지 판별한 데이터 ('p'는 독버섯, 'e'는 식용 버섯)
data=[] #독 버섯인지 판별에 필요한 데이터
for row_index, row in mr.iterrows():
label.append(row.loc[0]) #row.ix[0] 더 이상 지원하지 않는다.
other_data=[]
for v in row.loc[1:]:
other_data.append(v)
data.append(other_data)
print(label[0:5]) #너무 많아서 일부만 출력합니다.
print('====')
print(data[0:5]) #너무 많아서 일부만 출력합니다.
data의 알파벳을 수로 바꾸기
기계 학습에 관한 라이브러리들은 대부분 결과에 영향을 주는 입력 데이터 부분은 수만 취급하는 것이 많습니다. (동영상 강의를 보면 확인할 수 있어요.)
이를 위해 data에 보관할 데이터는 수로 취환할게요.
알파벳을 수로 취환하는 함수는 ord가 있습니다.
모든 데이터가 소문자일 때 ord(alpha)-ord(‘a’)+1 처럼 표현하면 1~26 사이의 수로 바뀝니다.
#파일 위치: https://ehpub.co.kr/files
#파일 이름: mushrooms.csv
import pandas as pd
mr = pd.read_csv("mushrooms.csv",header=None)
print(type(mr))
label=[] #독 버섯인지 판별한 데이터 ('p'는 독버섯, 'e'는 식용 버섯)
data=[] #독 버섯인지 판별에 필요한 데이터
for row_index, row in mr.iterrows():
label.append(row.loc[0]) #row.ix[0] 더 이상 지원하지 않는다.
other_data=[]
for v in row.loc[1:]:
other_data.append(ord(v)-ord('a')+1)
data.append(other_data)
print(label[0:5])
print('====')
print(data[0:5])
이상으로 강의를 마칠게요.