사용할 모듈 포함문
from sklearn.metrics import confusion_matrix #혼동 행렬
from sklearn.metrics import accuracy_score #적합도
from sklearn.metrics import recall_score #리콜(재현율, 민감도)
from sklearn.metrics import precision_score #정밀도
from sklearn.metrics import f1_score #F1 점
from sklearn.metrics import class_likelihood_ratios #우도
from sklearn.metrics import roc_auc_score #ROC AUC
from sklearn.metrics import roc_curve
from sklearn.metrics import RocCurveDisplay #ROC CURVE 시각화
from sklearn.metrics import auc
from sklearn.model_selection import cross_val_score #교차 검증 점수
from sklearn.metrics import classification_report #분류 레포트
from sklearn.linear_model import LogisticRegression #로지스틱 회귀
from sklearn.svm import SVC #서포트 벡터 머신
from sklearn.neighbors import KNeighborsClassifier #K 최근접 이웃
from sklearn.tree import DecisionTreeClassifier #결정 트리
from sklearn.ensemble import RandomForestClassifier #랜덤 포리스트
from sklearn.datasets import load_breast_cancer #유방암 데이터
from sklearn.datasets import fetch_covtype #산림 피복 데이터
from sklearn.model_selection import train_test_split #학습 및 테스트 데이터 분리
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')#경고 무시하기혼동 행렬
다중 분류를 평가하는 도구를 이해하기 위해 먼저 혼동 행렬을 소개할게요.
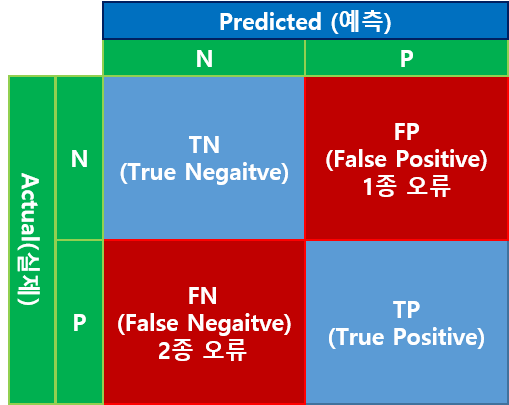
혼동 행렬은 실제 값과 예측 값의 분포를 행렬로 나타낸 것입니다.
이진 분류일 때 혼동 행렬은 4개(2X2)의 쉘로 구성합니다.
보통 컬럼 측은 예측 값을 표현하고 로우 값은 실제 값을 표현합니다.
위 그림에서 N은 부정을 의미하고 P는 긍정을 의미합니다.
TN은 실제 값이 부정이며 예측도 부정을 의미합니다. 따라서 T는 맞췄다는 의미이고 N은 예측을 Negative로 했음을 의미합니다.
FP는 실제 값은 부정인데 예측을 긍정으로 했음을 의미합니다. 잘못 예측한 것이죠. 이러한 오류를 1종 오류라고 부릅니다.
FN은 실제 값은 긍정인데 예측을 부정으로 했음을 의미합니다. 이러한 오류를 2종 오류라고 부릅니다.
TP는 실제 값과 예측 값 모두 긍정을 의미합니다.
다음은 부정 10개와 긍정 10개의 실제 값을 예측하였을 때의 예제입니다.
actual = np.array([0,0,0,0,0,0,0,0,0,0, #Negative
1,1,1,1,1,1,1,1,1,1]) #Positive
predicted = np.array([0,0,0,0,1,0,0,0,1,1, #Negative
1,1,1,1,0,0,1,1,1,1]) #Positive
print(confusion_matrix(actual,predicted))[out]
[[7 3]
[2 8]]결과를 보면 TN이 7개, FP가 3개입니다. 실제 거짓이 10개인데 이 중에 맞춘 것이 7개이고 잘못 판단해서 참으로 판단한 3개가 있다는 것이죠.
FN은 2개, TP는 8개입니다. 실제 참이 10개인데 이 중에 맞춘 것이 8개이고 틀린 것이 2개입니다.
Accuracy, Recall, Precision, F1, likelihood, ROC Curve
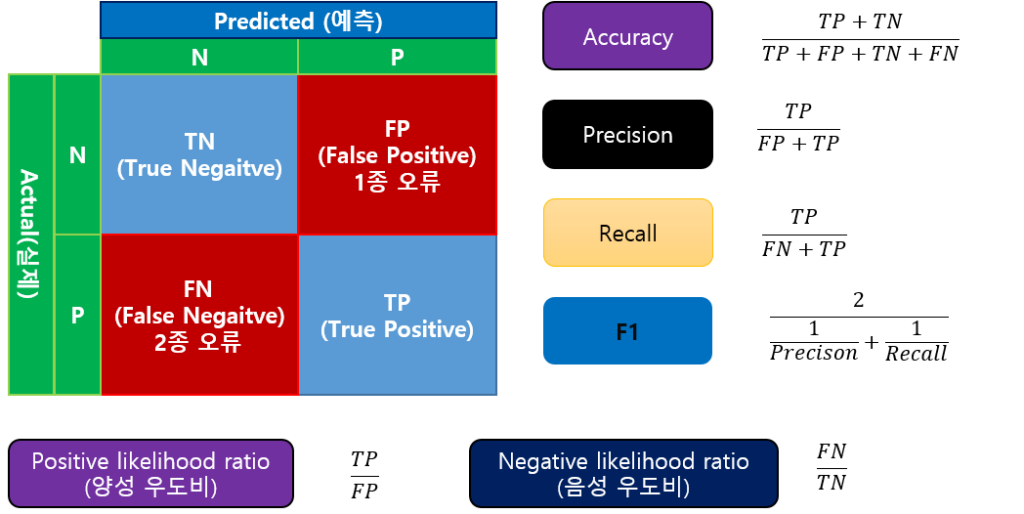
분류 모델의 평가 도구는 다양합니다.
여기에서는 Accuracy(정확도) , Precision(정밀도), Recall(재현율), F1, Likelihood ratio(우도비)를 살펴보기로 할게요.
- Accuracy
가장 대표적인 도구는 Accuracy(정확도)를 들 수 있습니다.
전체 중에 얼마다 맞췄는지를 평가하는 도구죠.
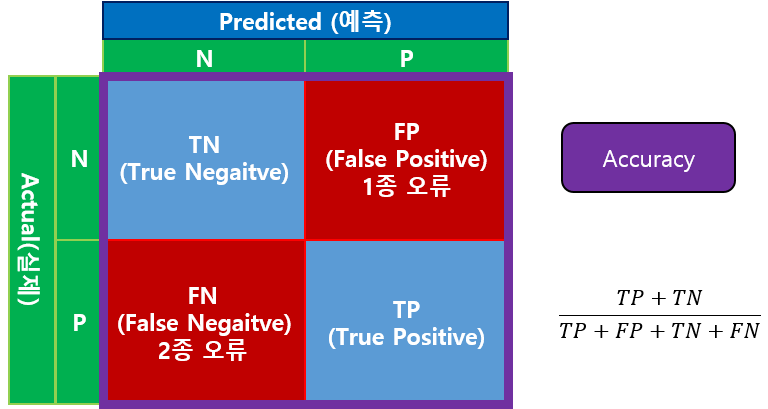
print("accuracy:",accuracy_score(actual,predicted)) #(7+8)/(7+3+2+8)=15/20[out]
accuracy: 0.75- Precison
Precison은 정밀도를 측정하는 도구입니다.
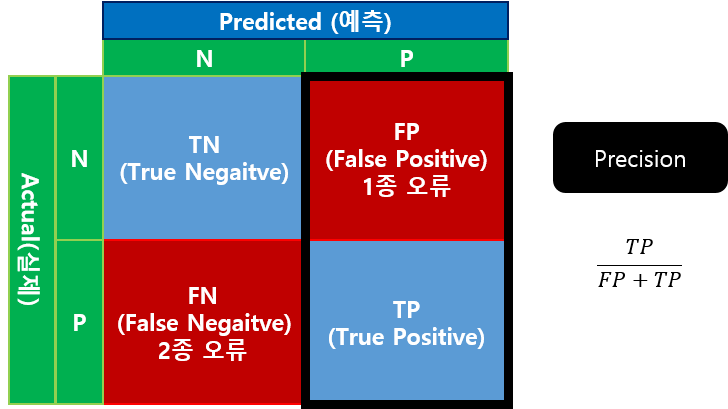
Precison은 긍정으로 예측한 것 중에 실제 긍정의 비율을 의미합니다.
스팸 메일이나 연락처 차단 등을 하려고 할 때 Precison이 높은 값이 나오는 것이 좋습니다.
스팸 메일이나 연락처 차단에서는 잘못 예측해서 중요한 정보를 차단하는 실수는 치명적일 수 있습니다.
실제 스팸이나 차단할 연락처가 아닌데 잘못 예측해서 차단해 버리는 것은 낭패인 것이죠.
반면 실제 스팸이거나 차단할 연락처인데 잘못 예측해서 차단하지 못하는 것은 불편하지만 치명적이지는 않습니다.
print("precision:",precision_score(actual,predicted)) #8/(3+8) = 8/11[out]
precision: 0.7272727272727273- Recall
Recall은 재현율을 측정하는 도구입니다.
Recall은 Sensitivity(민감도)라고도 부릅니다.
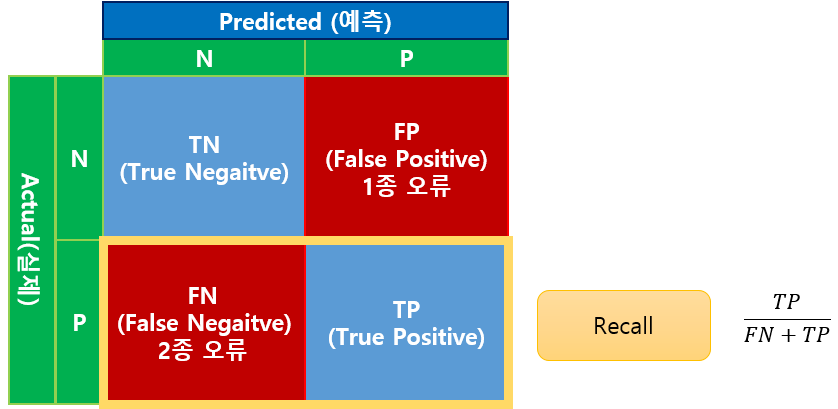
Recall은 실제 긍정 중에서 예측도 긍정으로 한 비율을 의미합니다.
병원에서 환자 진단에는 Recall이 높아야 합니다.
특정 병에 걸렸는데(실제 Positive) 예측을 잘못하여 걸리지 않았다고(예측 Negitive) 하는 것은 환자 건강 혹은 생명에 치명적일 수 있습니다.
반면 특정 병에 걸리지 않았는데(실제 Negative) 예측을 잘못하여 걸렸다고(예측 Positive) 하는 것은 비용이나 시간 낭비 등은 발생하겠지만 혼자 건강이나 생명에 치명적이지는 않습니다.
print("recall:",recall_score(actual,predicted)) #8/(2+8) = 8/10[out]
recall: 0.8- F1
F1은 Precision과 Recall의 조화 평균을 낸 것입니다.
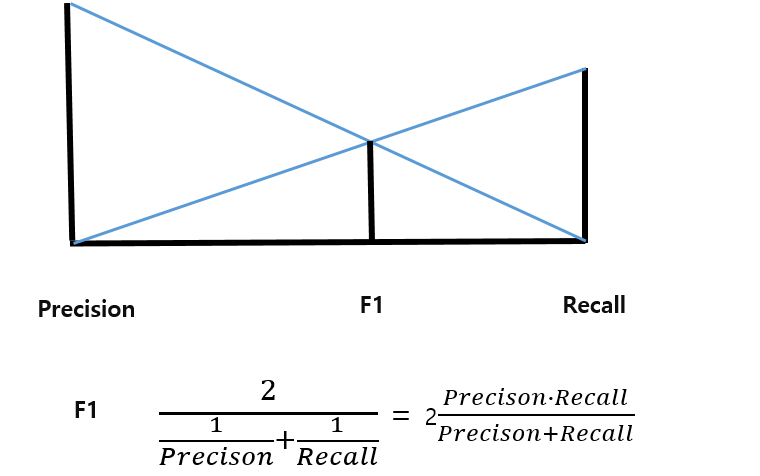
데이터가 긍정이나 부정 한쪽으로 쏠릴 때는 Accuracy 보다 F1을 더 선호할 수 있습니다.
print("f1:",f1_score(actual,predicted)) #2/(1/recall+1/precison) = 16/21[out]
f1: 0.761904761904762- Likelihood ratio
Likelihood ratio는 우도비를 측정 도구입니다.
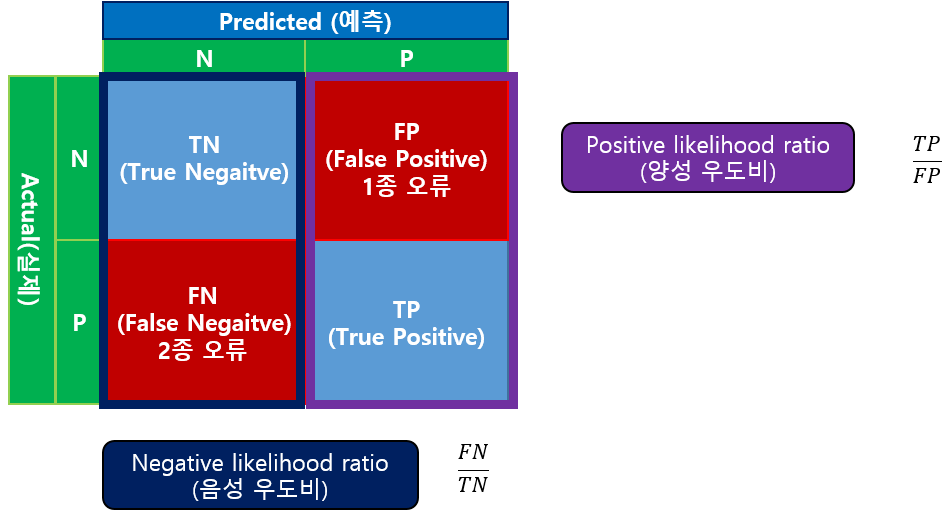
우도비는 양성 우도비와 음성 우도비로 구분할 수 있습니다.
양성 우도비(Positive likelihood ratio)는 긍정으로 예측 한 것 중에 실제 긍정과 부정인 것의 비율입니다.
양성 우도비는 클 수록 오판이 작음을 의미합니다.
음성 우도비(Nagative likelihood ratio)는 부정으로 예측한 것 중에 실제 긍정과 부정인 것의 비율입니다.)
음성 우도비는 작을 수록 오판이 작음을 의미합니다.
lh = class_likelihood_ratios(actual,predicted)
print("positive likelihood",lh[0]) #8/3
print("negative likelihood",lh[1]) #2/7[out]
positive likelihood 2.6666666666666665
negative likelihood 0.2857142857142857- ROC Curve
이러한 분류 모델 평가 도구 외에도 ROC curve 등이 있습니다.
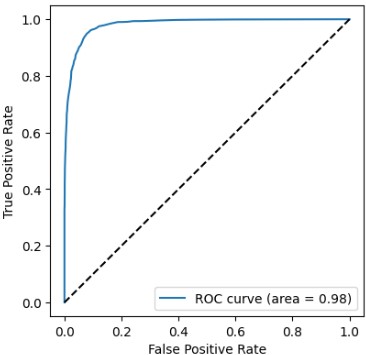
ROC curve는 x축을 True Positive Rate(Recall과 같은 값), y축을 False Positive Rate(TN/(TN+FP))로 표시한 curve를 의미합니다.
ROC AUC(Area Under the Curve)는 ROC Curve의 면적입니다.
ROC AUC 값은 최악일 때 0.5이고 최상일 때 1입니다.
print(f"roc auc:",roc_auc_score(actual,predicted))[out]
roc auc: 0.75다음은 지금까지 소개한 도구들을 사용한 코드입니다.
actual = np.array([0,0,0,0,0,0,0,0,0,0, #Negative
1,1,1,1,1,1,1,1,1,1]) #Positive
predicted = np.array([0,0,0,0,1,0,0,0,1,1, #Negative
1,1,1,1,0,0,1,1,1,1]) #Positive
print("confusion matrix\n",confusion_matrix(actual,predicted))
print("accuracy:",accuracy_score(actual,predicted)) #(7+8)/(7+3+2+8)=15/20
print("precision:",precision_score(actual,predicted)) #8/(3+8) = 8/11
print("recall:",recall_score(actual,predicted)) #8/(2+8) = 8/10
print("precision:",precision_score(actual,predicted)) #8/(3+8) = 8/11
print("f1:",f1_score(actual,predicted)) #2/(1/recall+1/precison) = 16/21
lh = class_likelihood_ratios(actual,predicted)
print("positive likelihood",lh[0]) #8/3
print("negative likelihood",lh[1]) #2/7
print(f"roc auc:",roc_auc_score(actual,predicted))[out]
confusion matrix
[[7 3]
[2 8]]
accuracy: 0.75
precision: 0.7272727272727273
recall: 0.8
precision: 0.7272727272727273
f1: 0.761904761904762
positive likelihood 2.6666666666666665
negative likelihood 0.2857142857142857
roc auc: 0.75유방암 데이터 분류(이진 분류)
이번에는 유방암 데이터를 가지고 머신 러닝 후에 평가 도구를 사용하는 실습을 해 봅시다.
먼저 데이터를 로딩하여 독립 변수와 종속 변수를 선언합시다.
종속 변수의 값 종류와 개수를 출력해 볼게요.
cancer = load_breast_cancer()
data = cancer.data
target = cancer.target
print(np.unique(target,return_counts=True))[out]
(array([0, 1]), array([212, 357]))유방암이 아닌 데이터가 212개 유방암인 데이터가 357개로 구성하고 있네요.
학습 데이터, 검증 데이터, 테스트 데이터로 분리합시다.
x_train_org,x_test, y_train_org,y_test = train_test_split(data[:30000],target[:30000])
x_train,x_val, y_train,y_val = train_test_split(x_train_org,y_train_org)
print(y_train.shape, y_val.shape, y_test.shape)[out]
(319,) (107,) (143,)학습 데이터 319, 검증 데이터 107, 테스트 데이터 143개입니다.
스케일 변환 전 후를 비교하기 위해 스케일 변환도 할게요.
mms = MinMaxScaler()
mms.fit(data)
x_train_s = mms.transform(x_train)
x_val_s = mms.transform(x_val)
x_test_s = mms.transform(x_test)실습할 모델을 생성합니다. 여기에서는 선형 회귀 모델, 서포트 벡터 머신, 최근접 이웃, 결정 트리, 랜덤 포레스트를 실험할게요.
model1 = LogisticRegression() #로지스틱 회귀
model2 = SVC() #서포트 벡터 머신
model3 = KNeighborsClassifier() #K 최근접 이웃
model4 = DecisionTreeClassifier() #결정 트리
model5 = RandomForestClassifier() #랜덤 포레스모델 마다 학습한 후 학습 데이터로 예측, 검증 데이터로 예측합시다.
평가 도구는 혼동 행렬, 적합도, 리콜, 정밀도를 측정할게요.
for model in [model1,model2,model3, model4, model5]:
print(model.__class__.__name__,"###")
model.fit(x_train,y_train)
pred_train = model.predict(x_train)
print("학습 데이터")
print(confusion_matrix(y_train,pred_train))
print(f"\t적합도:{accuracy_score(y_train,pred_train):.2f}")
print(f"\t리콜:{recall_score(y_train,pred_train):.2f}")
print(f"\t정밀도:{precision_score(y_train,pred_train):.2f}")
pred_val = model.predict(x_val)
print("검증 데이터")
print(confusion_matrix(y_val,pred_val))
print(f"\t적합도:{accuracy_score(y_val,pred_val):.2f}")
print(f"\t리콜:{recall_score(y_val,pred_val):.2f}")
print(f"\t정밀도:{precision_score(y_val,pred_val):.2f}")[out]
LogisticRegression ###
학습 데이터
[[108 9]
[ 5 197]]
적합도:0.96
리콜:0.98
정밀도:0.96
검증 데이터
[[32 4]
[ 3 68]]
적합도:0.93
리콜:0.96
정밀도:0.94
SVC ###
학습 데이터
[[ 91 26]
[ 3 199]]
적합도:0.91
리콜:0.99
정밀도:0.88
검증 데이터
[[28 8]
[ 3 68]]
적합도:0.90
리콜:0.96
정밀도:0.89
KNeighborsClassifier ###
학습 데이터
[[103 14]
[ 7 195]]
적합도:0.93
리콜:0.97
정밀도:0.93
검증 데이터
[[33 3]
[ 4 67]]
적합도:0.93
리콜:0.94
정밀도:0.96
DecisionTreeClassifier ###
학습 데이터
[[117 0]
[ 0 202]]
적합도:1.00
리콜:1.00
정밀도:1.00
검증 데이터
[[33 3]
[ 7 64]]
적합도:0.91
리콜:0.90
정밀도:0.96
RandomForestClassifier ###
학습 데이터
[[117 0]
[ 0 202]]
적합도:1.00
리콜:1.00
정밀도:1.00
검증 데이터
[[34 2]
[ 4 67]]
적합도:0.94
리콜:0.94
정밀도:0.97검증 데이터로 평가한 결과를 보면 적합도는 랜덤 포레스트가 제일 좋습니다.
리콜은 로지스틱 회귀와 서포트 벡터 모델이 좋네요.
정밀도는 랜덤 포레스트가 제일 좋네요.
전체적으로 보면 랜덤 포레스트가 제일 모델로 보입니다.
하지만 여기에서는 유방암 예측하는 것이므로 리콜에서 좋은 결과를 낸 로지스틱 회귀 혹은 서포트 벡터 모델이 적합하다고 볼 수도 있습니다.
스케일 조절한 데이터로도 같은 실험을 해 봅시다.
for model in [model1,model2,model3, model4, model5]:
print(model.__class__.__name__,"###")
model.fit(x_train_s,y_train)
pred_train = model.predict(x_train_s)
print("학습 데이터")
print(confusion_matrix(y_train,pred_train))
print(f"\t적합도:{accuracy_score(y_train,pred_train):.2f}")
print(f"\t리콜:{recall_score(y_train,pred_train):.2f}")
print(f"\t정밀도:{precision_score(y_train,pred_train):.2f}")
pred_val = model.predict(x_val_s)
print("검증 데이터")
print(confusion_matrix(y_val,pred_val))
print(f"\t적합도:{accuracy_score(y_val,pred_val):.2f}")
print(f"\t리콜:{recall_score(y_val,pred_val):.2f}")
print(f"\t정밀도:{precision_score(y_val,pred_val):.2f}")[out]
LogisticRegression ###
학습 데이터
[[106 11]
[ 0 202]]
적합도:0.97
리콜:1.00
정밀도:0.95
검증 데이터
[[31 5]
[ 0 71]]
적합도:0.95
리콜:1.00
정밀도:0.93
SVC ###
학습 데이터
[[113 4]
[ 0 202]]
적합도:0.99
리콜:1.00
정밀도:0.98
검증 데이터
[[34 2]
[ 1 70]]
적합도:0.97
리콜:0.99
정밀도:0.97
KNeighborsClassifier ###
학습 데이터
[[109 8]
[ 3 199]]
적합도:0.97
리콜:0.99
정밀도:0.96
검증 데이터
[[31 5]
[ 2 69]]
적합도:0.93
리콜:0.97
정밀도:0.93
DecisionTreeClassifier ###
학습 데이터
[[117 0]
[ 0 202]]
적합도:1.00
리콜:1.00
정밀도:1.00
검증 데이터
[[33 3]
[ 6 65]]
적합도:0.92
리콜:0.92
정밀도:0.96
RandomForestClassifier ###
학습 데이터
[[117 0]
[ 0 202]]
적합도:1.00
리콜:1.00
정밀도:1.00
검증 데이터
[[34 2]
[ 5 66]]
적합도:0.93
리콜:0.93
정밀도:0.97스케일 변환 후에도 리콜 점수는 로지스틱 회귀 모델이 제일 높은 점수를 내었네요.
최종적으로 로지스틱 회귀 모델로 최종 평가를 해 볼게요.
다음은 분류 모델 다양한 평가와 이를 출력하는 함수입니다.
def total_score_classifier(actual,predict,average='binary'):
print(confusion_matrix(actual,predict))
print(f"\t적합도:{accuracy_score(actual,predict):.2f}")
print(f"\t리콜:{recall_score(actual,predict,average=average):.2f}")
print(f"\t정밀도:{precision_score(actual,predict,average=average):.2f}")
print(f"\tF1:{f1_score(actual,predict,average=average):.2f}")다음은 ROC AUC 점수를 측정하고 이를 출력하고 도식하는 함수입니다.
def draw_roc_auc(actual,predict_proba):
print(f"\troc auc:{roc_auc_score(actual,predict_proba[:,1]):.2f}")
fpr, tpr, thresholds = roc_curve(actual, predict_proba[:,1])
roc_auc = auc(fpr, tpr)
display = RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc)
display.plot()로지스틱 회귀 모델로 학습 데이터, 검증 데이터, 테스트 데이터로 평가 측정하고 도식화해 봅시다.
final_model = LogisticRegression() #로지스틱 회귀
print(final_model.__class__.__name__,"###")
final_model.fit(x_train,y_train)
pred_train = final_model.predict(x_train)
print("학습 데이터")
total_score_classifier(y_train,pred_train)
pred_val = final_model.predict(x_val)
print("검증 데이터")
total_score_classifier(y_val,pred_val)
pred_test = final_model.predict(x_test)
print("테스트 데이터")
total_score_classifier(y_test,pred_test)
pred_test_proba = final_model.predict_proba(x_test)
draw_roc_auc(y_test, pred_test_proba)[out]
LogisticRegression ###
학습 데이터
[[108 9]
[ 5 197]]
적합도:0.96
리콜:0.98
정밀도:0.96
F1:0.97
검증 데이터
[[32 4]
[ 3 68]]
적합도:0.93
리콜:0.96
정밀도:0.94
F1:0.95
테스트 데이터
[[56 3]
[ 2 82]]
적합도:0.97
리콜:0.98
정밀도:0.96
F1:0.97
roc auc:1.00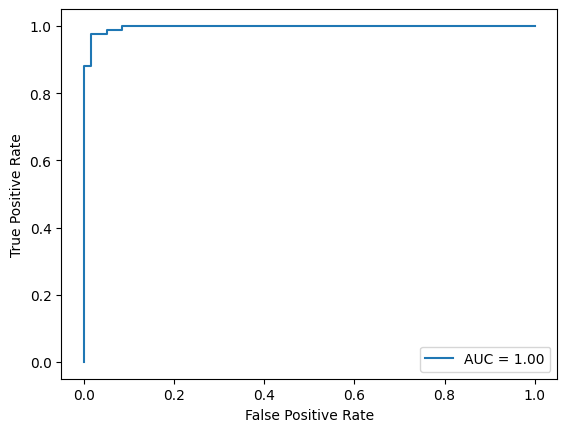
산림 피복 데이터 분류(다중 분류)
이번에는 다중 분류 작업을 해 봅시다.
데이터는 산림 피복 데이터입니다.
데이터를 로딩하고 독립 변수와 종속 변수를 선언합니다. (데이터를 로딩하는데 다소 시간이 걸릴 수 있습니다. Colab 기준 1분)
covtype = fetch_covtype()
data = covtype.data
target = covtype.target종속 변수의 값의 분포를 간단히 확인할게요.
np.unique(covtype.target,return_counts=True)[out]
(array([1, 2, 3, 4, 5, 6, 7], dtype=int32),
array([211840, 283301, 35754, 2747, 9493, 17367, 20510]))7 종류로 구분했는데 다음과 같다고 하네요.
1 – Neota
2 – Comanche Peak
3 – Cache la Poudre
4 – cottonwood
5 – spruce-fir
6 – douglar-fir
7 – etc
데이터가 너무 많아서 이 중에 30000만 개만 사용할게요. 먼저 분포가 고른지 확인해 볼게요.
np.unique(target[:30000],return_counts=True)[out]
(array([1, 2, 3, 4, 5, 6, 7], dtype=int32),
array([ 4772, 14192, 2160, 2160, 2396, 2160, 2160]))아주 고른 분포는 아니지만 실험하는 데 큰 문제는 없어 보이네요.
학습 데이터, 검증 데이터, 테스트 데이터로 분리합시다.
x_train_org,x_test, y_train_org,y_test = train_test_split(data[:30000],target[:30000])
x_train,x_val, y_train,y_val = train_test_split(x_train_org,y_train_org)
print(y_train.shape, y_val.shape, y_test.shape)[out]
(16875,) (5625,) (7500,)소요 시간 및 적합도 평가
이번에도 5가지 모델을 가지고 실험합시다.
model1 = LogisticRegression() #선형
model2 = SVC() #서포트 벡터 머신
model3 = KNeighborsClassifier() #K 최근접 이웃
model4 = DecisionTreeClassifier() #결정 트리
model5 = RandomForestClassifier() #랜덤 포레스트 이번에는 학습 및 예측에 걸리는 시간도 측정합시다.
for model in [model1, model2,model3, model4, model5]:
ex_times=[]
print(model.__class__.__name__,"###")
start = time.time()
model.fit(x_train,y_train)
stop = time.time()
ex_times.append(stop - start)
start = time.time()
pred_train = model.predict(x_train)
stop = time.time()
ex_times.append(stop - start)
print("학습 데이터 적합도:",accuracy_score(y_train,pred_train))
start = time.time()
pred_val = model.predict(x_val)
stop = time.time()
ex_times.append(stop - start)
print("검증 데이터 적합도:",accuracy_score(y_val,pred_val))
print("소요 시간:",np.round(ex_times,3))[out]
LogisticRegression ###
학습 데이터 적합도: 0.5990518518518518
검증 데이터 적합도: 0.6046222222222222
소요 시간: [0.838 0.003 0.001]
SVC ###
학습 데이터 적합도: 0.7111111111111111
검증 데이터 적합도: 0.7096888888888889
소요 시간: [ 8.545 11.986 3.805]
KNeighborsClassifier ###
학습 데이터 적합도: 0.922074074074074
검증 데이터 적합도: 0.8624
소요 시간: [0.002 1.486 0.528]
DecisionTreeClassifier ###
학습 데이터 적합도: 1.0
검증 데이터 적합도: 0.8522666666666666
소요 시간: [0.183 0.003 0.002]
RandomForestClassifier ###
학습 데이터 적합도: 1.0
검증 데이터 적합도: 0.9016888888888889
소요 시간: [2.581 0.306 0.116]평가 점수는 랜덤 포레스트, 최근접 이웃, 결정 트리, 서포트 벡터, 로지스틱 회귀 순으로 좋네요.
소요 시간은 서포트 벡터와 랜덤 포레스트가 오래 걸리고 나머지는 빠르게 수행하네요.
최근접 이웃은 학습은 거의 0초에 근접하며 오히려 예측에 더 오래 걸리네요. 이 부분은 별도로 최근접 이웃 모델 내부를 소개할 때 얘기하기로 할게요.
스케일 변환 후 테스트
스케일 변환 후 테스트는 최근접 이웃, 결정 트리, 랜덤 로레스트 모델만 가지고 할게요.
mms = MinMaxScaler()
mms.fit(data)
x_train_s = mms.transform(x_train)
x_val_s = mms.transform(x_val)
x_test_s = mms.transform(x_test)model3 = KNeighborsClassifier() #K 최근접 이웃
model4 = DecisionTreeClassifier() #결정 트리
model5 = RandomForestClassifier() #랜덤 포레스트 적합도만 확인해 볼게요.
for model in [model3, model4, model5]:
print(model.__class__.__name__,"###")
model.fit(x_train_s,y_train)
pred_train = model.predict(x_train_s)
print("학습 데이터 적합도:",accuracy_score(y_train,pred_train))
pred_val = model.predict(x_val_s)
print("검증 데이터 적합도:",accuracy_score(y_val,pred_val))[out]
KNeighborsClassifier ###
학습 데이터 적합도: 0.9031111111111111
검증 데이터 적합도: 0.8602666666666666
DecisionTreeClassifier ###
학습 데이터 적합도: 1.0
검증 데이터 적합도: 0.8608
RandomForestClassifier ###
학습 데이터 적합도: 1.0
검증 데이터 적합도: 0.9109333333333334검증 데이터 기준으로 보면 랜덤 포레스트 모델이 제일 좋네요.
최종 확인
랜덤 포레스트 모델로 최종 평가해 봅시다.
사이킷 런에서는 total_score_classifier 함수를 제공하고 있습니다.
final_model = RandomForestClassifier() #랜덤 포리스트 회귀
print(final_model.__class__.__name__,"###")
final_model.fit(x_train,y_train)
pred_train = final_model.predict(x_train)
print("학습 데이터")
total_score_classifier(y_train,pred_train,average='macro')
pred_val = final_model.predict(x_val)
print("검증 데이터")
total_score_classifier(y_val,pred_val,average='macro')
pred_test = final_model.predict(x_test)
print("테스트 데이터")
total_score_classifier(y_test,pred_test,average='macro')
print(classification_report(y_test,pred_test))[out]
RandomForestClassifier ###
학습 데이터
[[2645 0 0 0 0 0 0]
[ 0 7974 0 0 0 0 0]
[ 0 0 1219 0 0 0 0]
[ 0 0 0 1228 0 0 0]
[ 0 0 0 0 1348 0 0]
[ 0 0 0 0 0 1214 0]
[ 0 0 0 0 0 0 1247]]
적합도:1.00
리콜:1.00
정밀도:1.00
F1:1.00
검증 데이터
[[ 712 144 1 0 14 0 22]
[ 88 2508 15 0 43 14 5]
[ 0 1 325 20 4 47 0]
[ 0 0 8 385 0 2 0]
[ 1 30 6 0 410 7 0]
[ 0 0 48 11 6 352 0]
[ 14 2 0 0 0 0 380]]
적합도:0.90
리콜:0.89
정밀도:0.88
F1:0.89
테스트 데이터
[[ 958 225 0 0 15 3 33]
[ 121 3340 12 0 54 13 5]
[ 0 3 418 33 10 80 0]
[ 0 0 12 519 0 6 0]
[ 0 40 10 0 535 9 0]
[ 1 1 54 15 6 452 0]
[ 17 1 0 0 2 0 497]]
적합도:0.90
리콜:0.88
정밀도:0.88
F1:0.88
precision recall f1-score support
1 0.87 0.78 0.82 1234
2 0.93 0.94 0.93 3545
3 0.83 0.77 0.80 544
4 0.92 0.97 0.94 537
5 0.86 0.90 0.88 594
6 0.80 0.85 0.83 529
7 0.93 0.96 0.94 517
accuracy 0.90 7500
macro avg 0.88 0.88 0.88 7500
weighted avg 0.90 0.90 0.89 7500다음은 다중 분류에서 ROC Curve를 도식하는 코드입니다.
먼저 종속 변수를 원-핫 인코딩합니다.
from sklearn.preprocessing import OneHotEncoder
y_test_one = OneHotEncoder().fit_transform(y_test.reshape(-1,1)).toarray()
print(y_test_one.shape)[out]
(7500, 7)다음은 원-핫 인코딩 전 후의 종속 변수를 확인하는 코드입니다. 여기에서는 테스트 데이터의 10개의 종속 변수로 확인하고 있습니다.
print(y_test[:10])
print(y_test_one[:10])[out]
[2 1 6 1 2 2 2 2 6 4]
[[0. 1. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0.]
[1. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 1. 0. 0. 0.]]보면 2를 [0. 1. 0. 0. 0. 0. 0.]로 변환한 것입니다.
1은 [1. 0. 0. 0. 0. 0. 0.]으로 변환하였습니다.
6은 [0. 0. 0. 0. 0. 1. 0.]으로 변환하였습니다.
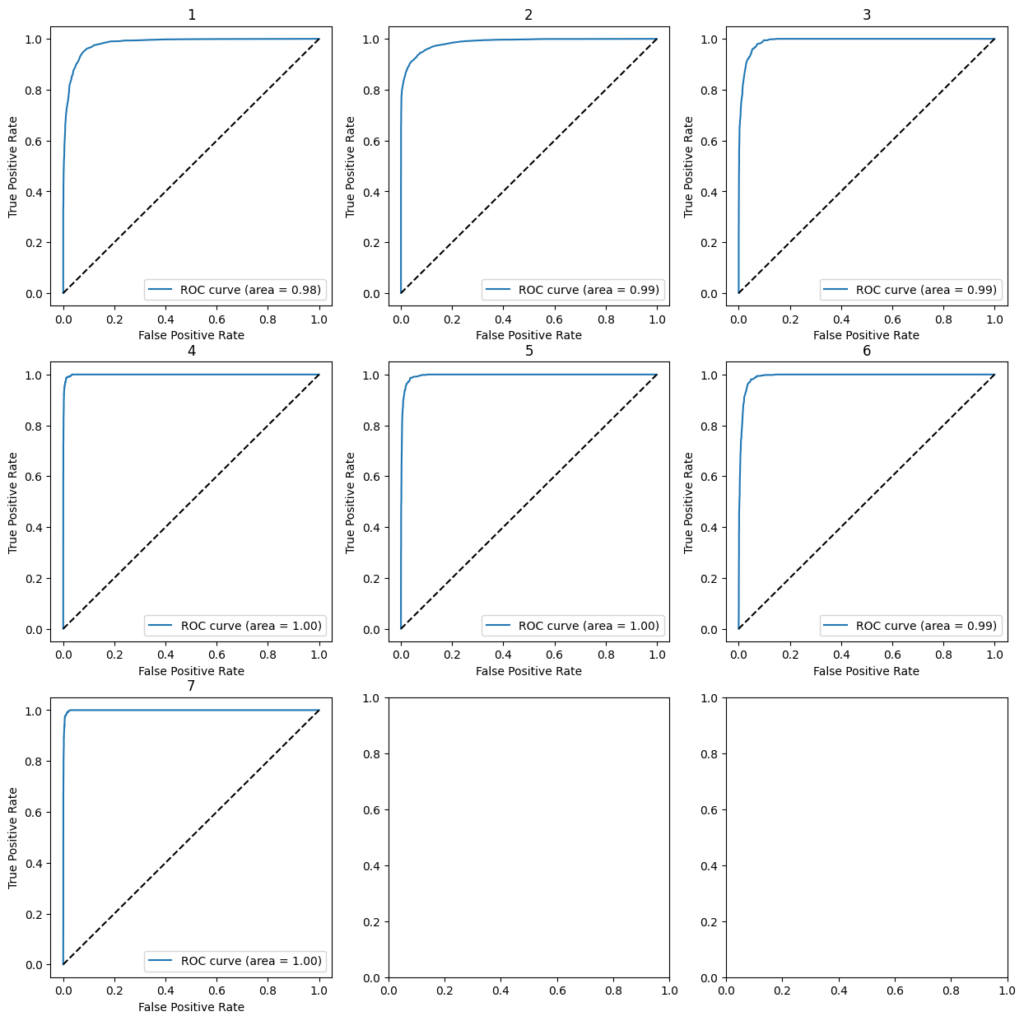
다음은 다중 분류에서 ROC Curve를 도식하는 예제 코드입니다.
pred_test_proba = final_model.predict_proba(x_test)
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(7):
fpr[i], tpr[i], _ = roc_curve(y_test_one[:,i], pred_test_proba[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
fig, axs = plt.subplots(nrows=3,ncols=3,figsize=(15,15))
for i in range(7):
ax = axs[i//3,i%3]
ax.plot(fpr[i], tpr[i], label='ROC curve (area = %0.2f)' % roc_auc[i])
ax.plot([0, 1], [0, 1], 'k--')
ax.set_xlabel('False Positive Rate')
ax.set_ylabel('True Positive Rate')
ax.set_title(str(i+1))
ax.legend(loc="lower right")
plt.show()
print("roc_auc_score: ", roc_auc_score(y_test_one, pred_test_proba, multi_class='raise'))[out]
roc_auc_score: 0.9919409462337846