
사용할 모듈 포함문
from sklearn.preprocessing import Binarizer #이항 변수화 변환
from sklearn.metrics import recall_score #리콜(재현율, 민감도)
from sklearn.metrics import precision_score #정밀도
from sklearn.metrics import confusion_matrix #혼동 행렬
from sklearn.metrics import accuracy_score #적합도
from sklearn.metrics import f1_score #F1 점수
from sklearn.datasets import load_breast_cancer #유방암 데이터
from sklearn.linear_model import LogisticRegression #로지스틱 회귀
from sklearn.model_selection import train_test_split #학습 및 테스트 데이터 분리
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt이번 글에서는 Binarizer를 이용하여 recall과 precision 값을 조절하는 실습을 해 볼게요.
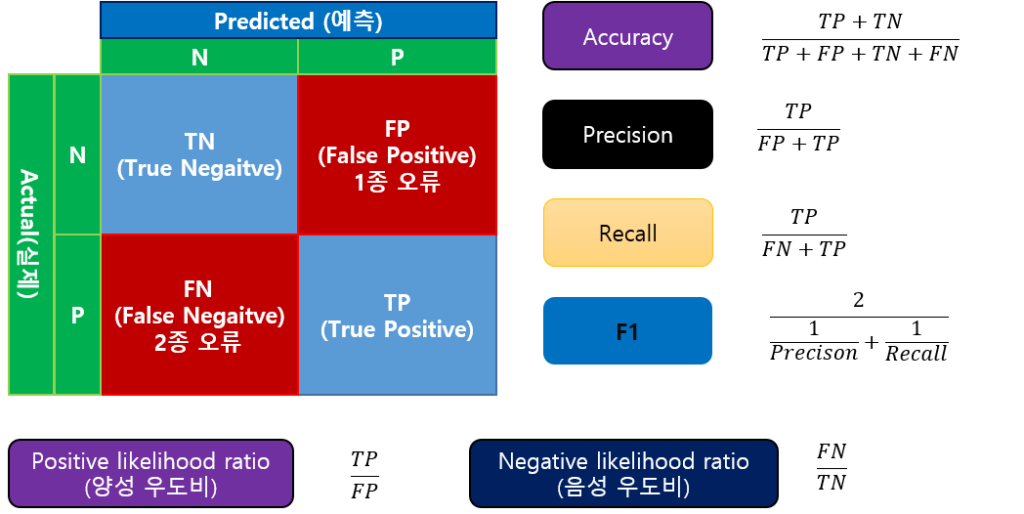
분류 모델의 평가 도구 중에 Accuracy와 F1은 일반적인 평가에서 많이 사용합니다.
여기에 보다 세밀하게 평가하기 위해 Recall이나 Precison 등을 사용합니다.
특히 분류하는 목적에 따라 1종 오류(FP, 실제 값은 부정인데 예측은 긍정)를 회피해야 하는 문제에서는 Precision이 높은 것이 좋습니다.
2종 오류(FN, 실제 값은 긍정인데 예측은 부정)을 회피해야 하는 문제에서는 Recall이 높은 것이 좋습니다.
예를 들어 스팸이나 Call 차단 서비스에서는 1종 오류를 피해야 합니다. (스팸 -긍정, 스팸 아님 – 부정)
1종 오류가 발생한다는 것은 스팸이 아닌데 스팸으로 판단하여 차단해 버리는 것이기 때문에 중요한 메일이나 Call을 받지 못하는 상황이 발생합니다.
오히려 이러한 문제에서는 2종 오류는 치명적이지는 않습니다. 스팸이나 Call 차단 필터링을 못한 것이 있어도 다소 불편할 뿐이죠.
하지만 환자의 병 진단은 반대로 2종 오류를 피해야 합니다. (병에 걸림 – 긍정, 병에 걸리지 않음 – 부정)
2종 오류가 발생했다는 것은 병에 걸렸는데 병에 걸리지 않은 것으로 예측한 것입니다. 이는 환자가 제대로 치료할 적기를 놓쳐 건강이나 생명에 치명적일 수 있다는 것입니다.
반면 이러한 문제에서는 1종 오류는 2종 오류에 비해 치명적이지는 않습니다. 병에 걸리지 않은 환자를 병에 걸렸다고 하더라도 시간이나 비용 증가 등의 문제가 발생하는 정도의 문제가 발생할 따름이죠.
물론 필요 없는 수술을 하는 등의 상황이 발생하면 이 또한 치명적일 수는 있지만 그렇다고 해도 병 진단에서는 2종 오류를 줄이는 것이 더 나은 선택일 것입니다.
예를 들어 어떤 환자가 위암일 확률이 30%일 때 의사는 환자에게 위암일 수도 있으니 좀 더 확인을 해 보자고 권유하는 것이 나은 선택일 것입니다.
이번 실습에서는 예측 값의 확률을 원하는 기준으로 긍정 혹은 부정으로 결론 내려 Recall과 Precision 값을 조절하는 실습을 할 것입니다.
유방암 데이터 분류 작업 (이진 분류)
실습할 데이터는 유방암 데이터 분류 작업을 예로 들게요.
이 작업은 이미 분류 작업의 평가 도구에서 살펴본 예입니다.
먼저 데이터를 로딩한 후 학습 데이터, 검증 데이터, 테스트 데이터로 분리합시다.
cancer = load_breast_cancer()
data = cancer.data
target = cancer.target
x_train_org,x_test, y_train_org,y_test = train_test_split(data[:30000],target[:30000])
x_train,x_val, y_train,y_val = train_test_split(x_train_org,y_train_org)
print(y_train.shape, y_val.shape, y_test.shape)[out]
(319,) (107,) (143,)스케일을 변환도 진행합시다. (이전 실습에서 미미하게 스케일 변환하였을 때 결과가 좋았습니다.)
mms = MinMaxScaler()
mms.fit(data)
x_train_s = mms.transform(x_train)
x_val_s = mms.transform(x_val)
x_test_s = mms.transform(x_test)로지스틱 회귀 모델로 학습 후 검증 및 평가를 해 봅시다.
model = LogisticRegression() #로지스틱 회귀
print(model.__class__.__name__,"###")
model.fit(x_train_s,y_train)
pred_train = model.predict(x_train_s)
print("학습 데이터")
print(confusion_matrix(y_train,pred_train))
print(f"\t적합도:{accuracy_score(y_train,pred_train):.2f}")
print(f"\t리콜:{recall_score(y_train,pred_train):.2f}")
print(f"\t정밀도:{precision_score(y_train,pred_train):.2f}")
pred_val = model.predict(x_val_s)
print("검증 데이터")
print(confusion_matrix(y_val,pred_val))
print(f"\t적합도:{accuracy_score(y_val,pred_val):.2f}")
print(f"\t리콜:{recall_score(y_val,pred_val):.2f}")
print(f"\t정밀도:{precision_score(y_val,pred_val):.2f}")
pred_test = model.predict(x_test_s)
print("평가 데이터")
print(confusion_matrix(y_test,pred_test))
print(f"\t적합도:{accuracy_score(y_test,pred_test):.2f}")
print(f"\t리콜:{recall_score(y_test,pred_test):.2f}")
print(f"\t정밀도:{precision_score(y_test,pred_test):.2f}")[out]
LogisticRegression ###
학습 데이터
[[117 9]
[ 1 192]]
적합도:0.97
리콜:0.99
정밀도:0.96
검증 데이터
[[34 2]
[ 0 71]]
적합도:0.98
리콜:1.00
정밀도:0.97
평가 데이터
[[47 3]
[ 0 93]]
적합도:0.98
리콜:1.00
정밀도:0.97여기까지는 이전 글에서 실습한 내용과 흡사합니다.
Binarizer
class sklearn.preprocessing.Binarizer(*, threshold=0.0, copy=True)
Binarizer 메뉴얼 사이트
Binarizer는 변수의 값을 이항 변수로 변환하는 클래스입니다.
독립 변수를 원하는 기준(threshold)으로 0과 1로 변환하는 작업에 사용합니다.
여기에서는 이를 Recall과 Precision을 조절하는데 사용할 것입니다.
먼저 간단히 Binarizer 사용 방법을 살펴봅시다.
사용할 데이터는 start=0.1, stop=0.9, step=0.1인 데이터입니다.
이를 0.1, 0.3, 0.5, 0.7, 0.9를 기준으로 데이터 변환하는 작업입니다.
dum_data = [ [round(value,1)] for value in np.arange(0.1,1.0,0.1)]
print("data:",dum_data)
for th_value in [0.1, 0.3, 0.5, 0.7, 0.9]:
binarizer = Binarizer(threshold=th_value)
print(th_value,end=' : ')
result = binarizer.transform(dum_data)
print(result.tolist())[out]
data: [[0.1], [0.2], [0.3], [0.4], [0.5], [0.6], [0.7], [0.8], [0.9]]
0.1 : [[0.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]]
0.3 : [[0.0], [0.0], [0.0], [1.0], [1.0], [1.0], [1.0], [1.0], [1.0]]
0.5 : [[0.0], [0.0], [0.0], [0.0], [0.0], [1.0], [1.0], [1.0], [1.0]]
0.7 : [[0.0], [0.0], [0.0], [0.0], [0.0], [0.0], [0.0], [1.0], [1.0]]
0.9 : [[0.0], [0.0], [0.0], [0.0], [0.0], [0.0], [0.0], [0.0], [0.0]]결과를 보면 threshold 값에 따라 원래 값이 0 혹은 1로 변환하는 것을 알 수 있습니다.
Recall과 Precision 조절하기
이제 유방암 데이터를 예측하였을 때의 확률을 원하는 기준(threshold)에 따라 긍정과 부정으로 변환해 봅시다. 이를 통해 Recall과 Precision을 조절할 수 있습니다.
model = LogisticRegression() #로지스틱 회귀
print(model.__class__.__name__,"###")
model.fit(x_train_s,y_train)
pred_test_p = model.predict_proba(x_test_s)
pred_test_p2 = pred_test_p[:,-1].reshape(-1,1)
scores=[]
for th_value in [0.3, 0.4, 0.5, 0.6, 0.7]:
print("threshold:",th_value)
binarizer = Binarizer(threshold=th_value)
result = binarizer.transform(pred_test_p2)
print(confusion_matrix(y_test,result))
acc = accuracy_score(y_test,result)
rec = recall_score(y_test,result)
pre = precision_score(y_test,result)
scores.append([acc,rec,pre])
print(f"\t적합도:{acc:.2f} 리콜:{rec:.2f} 정밀도:{pre:.2f}")[out]
LogisticRegression ###
threshold: 0.3
[[42 8]
[ 0 93]]
적합도:0.94 리콜:1.00 정밀도:0.92
threshold: 0.4
[[46 4]
[ 0 93]]
적합도:0.97 리콜:1.00 정밀도:0.96
threshold: 0.5
[[47 3]
[ 0 93]]
적합도:0.98 리콜:1.00 정밀도:0.97
threshold: 0.6
[[49 1]
[ 2 91]]
적합도:0.98 리콜:0.98 정밀도:0.99
threshold: 0.7
[[49 1]
[ 7 86]]
적합도:0.94 리콜:0.92 정밀도:0.99이를 시각화해 봅시다.
acc_scores = [score[0] for score in scores]
rec_scores = [score[1] for score in scores]
pre_scores = [score[2] for score in scores]
fig,axs = plt.subplots(ncols=2,figsize=(10,5))
axs[0].plot(acc_scores,label='accuracy')
axs[0].legend()
axs[1].plot(rec_scores,'r',label='recall')
axs[1].plot(pre_scores,'b:',label='precision')
axs[1].legend()
plt.show()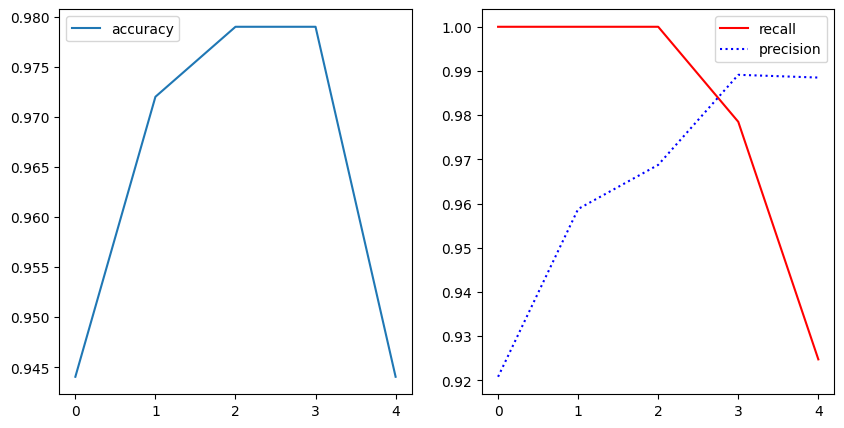
Recall과 Precison 점수는 threshold에 따라 한쪽이 올라가면 다른 한쪽은 내려가는 형태를 지님을 알 수 있습니다.
1종 오류를 줄여야 하는 문제인지 2종 오류를 줄여야 하는 문제인지에 따라 조절할 수 있으면 나은 결과를 얻을 수 있습니다.