사용할 모듈 포함문
from sklearn import datasets #머신 러닝 학습에 사용할 수 있는 데이터들
from sklearn.preprocessing import MinMaxScaler #전처리 공정 중에 MinMaxScaler
from sklearn.model_selection import train_test_split #데이터를 학습 및 테스트 용으로 분리
from sklearn import neighbors,linear_model #이웃 및 선형 모델
from sklearn.metrics import accuracy_score #평가 방법 중에 적합도
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt테스트에 사용할 데이터
첫 번째 머신러닝에 사용할 데이터는 붓꽃 데이터입니다.
사이킷 런(sklearn)에서는 datasets 모듈을 통해 머신러닝 학습에 사용할 수 있는 몇 가지 데이터를 제공하고 있습니다.
그 중에 이번에는 붓꽃 데이터를 사용할 거예요.
iris = datasets.load_iris() #붓꽃 데이터 로드붓꽃 데이터의 키 목록을 확인해 봅시다.
print(iris.keys())[out]
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])키 별로 데이터 타입을 확인한 후에 하나씩 살펴볼게요.
for key in iris.keys():
print(key,":",type(iris[key]))[out]
data : <class 'numpy.ndarray'>
target : <class 'numpy.ndarray'>
frame : <class 'NoneType'>
target_names : <class 'numpy.ndarray'>
DESCR : <class 'str'>
feature_names : <class 'list'>
filename : <class 'str'>
data_module : <class 'str'>iris.data
data가 무엇인지 먼저 살펴볼게요. (feature_names 키도 data 설명에 필요합니다.)
print(iris.data[0])
print(iris.data.shape)
print(iris.feature_names)[out]
[5.1 3.5 1.4 0.2]
(150, 4)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']결과를 보면 4개의 특성을 갖는 150개의 데이터로 구성하고 있습니다.
그리고 각 특성은 꽃받침(sepal) 길이와 너비, 꽃잎(petal) 길이와 너비를 의미합니다.
iris.target
target이 무엇인지 알아봅시다. (target_names 키도 target 설명에 필요합니다.)
print(iris.target .shape)
print(np.unique(iris.target,return_counts=True))
print(iris.target_names)[out]
(150,)
(array([0, 1, 2]), array([50, 50, 50]))
['setosa' 'versicolor' 'virginica']결과를 보면 data의 개수처럼 150개입니다.
그리고 값의 종류는 0, 1, 2 이며 각 50개씩 있네요.
타겟 이름은 0은 setosa, 1은 versicolor, 2는 virginica임을 알 수 있어요.
여기에서는 iris.data를 독립변수, iris.target을 종속변수로 사용할 원본 데이터입니다.
데이터 전처리
독립변수는 학습 목적과 모델링 과정에서 보다 나은 결과를 위해 전처리 작업을 할 수 있습니다.
결측치 처리나 이상값 처리 외에도 전처리 작업에서 하는 일은 다양합니다.
여기에서는 독립변수의 크기를 일정하게 조절하는 작업을 할게요.
스케일 변환 방법은 크게 표준 점수로 스케일 조절하는 StandardScaler를 이용하는 방법과 0~1 사이의 값으로 조절하는 MinMaxScaler 등이 있습니다.
여기에서는 MinMaxScaler를 사용할게요.
mms = MinMaxScaler()
x_data = mms.fit_transform(iris.data)스케일 조절하기 전과 후의 값의 기초 통계를 확인해 볼게요.
o_df = pd.DataFrame(iris.data)
display(o_df.describe())
df = pd.DataFrame(x_data)
display(df.describe())[out]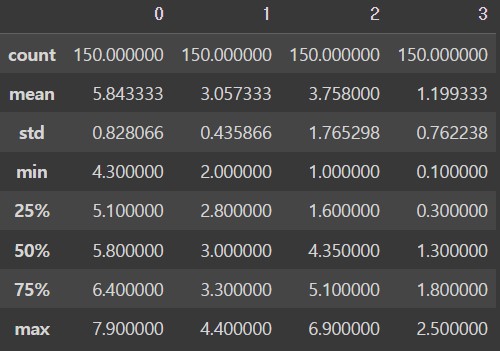
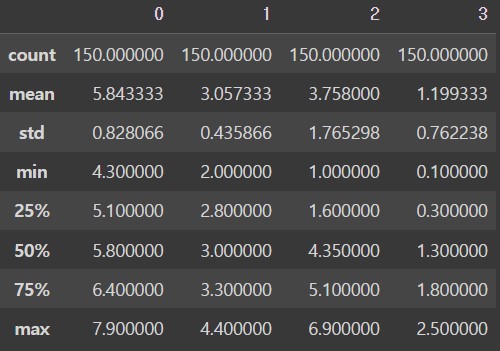
변환 후 값을 보면 모든 컬럼의 최솟값은 0, 최댓값은 1로 바뀐 것을 알 수 있습니다.
참고로 MinMaxScaler에 의해 변환한 값은 (표본-최솟값)/(최댓값-최솟값) 입니다.
모델 학습하기 전에 학습에 사용할 데이터와 테스트(평가)에 사용할 데이터로 분리합니다.
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
train_test_split 메뉴얼 사이트
x_train, x_test, y_train, y_test = train_test_split(x_data, iris.target)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)[out]
(112, 4) (38, 4) (112,) (38,)기본적으로 75%는 학습 데이터, 25%는 평가 데이터로 분리합니다. 원하는 크기로 조절하기 원한다면 test_size 옵션을 이용하세요.
학습 데이터는 다시 실제 학습 데이터와 검증 데이터로 분리하는 것을 권장합니다.
x_train2, x_val, y_train2, y_val = train_test_split(x_train, y_train)
print(x_train2.shape, x_val.shape, y_train2.shape, y_val.shape)[out]
(84, 4) (28, 4) (84,) (28,)모델링 (데이터 학습)
모델링 작업에서는 다양한 모델로 학습하고 예측 결과를 확인하고 더 나은 모델을 찾는 작업을 수행합니다.
이를 위해 데이터를 다시 가공하거나 모델에 하이퍼 파라미터를 바꾸는 등의 다양한 작업을 수행합니다.
여기에서는 두 가지 모델(로지스틱 회귀, K-최근접 이웃)을 이용하여 분류 학습을 해 보기로 할게요.
로지스틱 회귀는 이름은 회귀 모델이지만 실제 분류 작업에 사용합니다.
모델을 생성한 후에 학습은 모델의 fit 메서드를 이용하고 예측은 predict 메서드를 이용합니다.
예측을 잘 하는지 평가하는 방법은 여러 가지 방법이 있는데 여기에서는 적합도(accuracy)로 평가할게요.
model1 = linear_model.LogisticRegression()
model2 = neighbors.KNeighborsClassifier()
for model in [model1,model2]:
print(model.__class__.__name__,"###")
model.fit(x_train2,y_train2)
val_pred = model.predict(x_val)
print(f"accuray:{accuracy_score(val_pred,y_val):.3f}")[out]
LogisticRegression ###
accuray:0.750
KNeighborsClassifier ###
accuray:0.964두 개의 모델 중에 KNeighborsClassifier 모델이 더 나은 점수를 얻었네요.
최종 평가는 테스트 데이터로 수행합니다.
print("선정 모델:",model2.__class__.__name__)
test_pred = model2.predict(x_test)
print(f"최종 accuray:{accuracy_score(test_pred,y_test):.3f}")[out]
선정 모델: KNeighborsClassifier
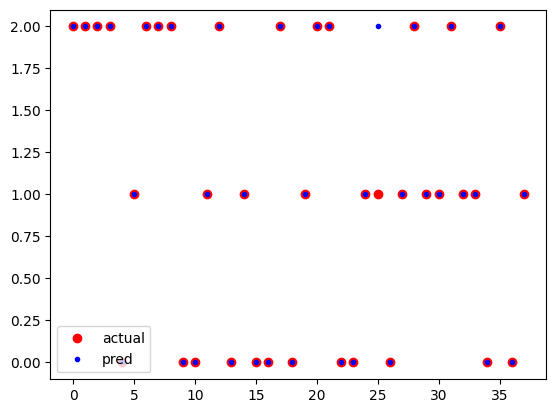
최종 accuray:0.974예측 값과 실제 값을 도식화 해 볼게요.
plt.plot(y_test,'ro',label='actual')
plt.plot(test_pred,'b.',label='pred')
plt.legend()
plt.show()