
알고리즘
부분 문자열 비교(str1:비교 대상 문자열1, str2: 비교 대상 문자열 2, n:비교할 문자 개수)
….반복(n이 0보다 크면서 str이 가리키는 문자가 참이면서 str1과 str2가 가리키는 문자가 서로 같으면)
……..str1과 str2를 다음 위치로 이동
……..n을 1 감소
….str1과 str2가 가리키는 문자의 차이 반환
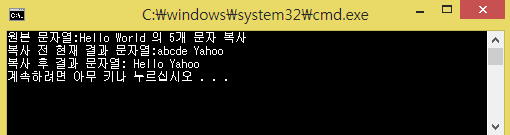
소스코드
//부분 문자열 비교하는 함수 만들기
#include <stdio.h>
int mystrlen(const char *str);
//사전식 비교: 사전에 앞에 나오는 단어가 작고 뒤에 나오는 단어가 크다고 판별
//차이가 없으면 0 반환
int mystrncmp(const char *str1, const char *str2, size_t n);
int main(void)
{
char src[100] = "This is test1. He is a student. She is a teacher.";
char key[10] = "is";
int len;
int i;
len = mystrlen(key);
printf("원본 문자열:%s\n\n", src);
printf("is로 시작하는 부분 문자열 목록\n\n");
for (i = 0; src[i]; i++)
{
if (mystrncmp(src + i, key, len) == 0)//부분 문자열 비교 결과가 0일 때
{
printf("%s\n", src + i);
}
}
return 0;
}
int mystrlen(const char *str)
{
int cnt;
//str[cnt]가 거짓 문자(종료 문자, '\0')가 나올 때까지 cnt를 1증가
for (cnt = 0; str[cnt]; cnt++);
return cnt;
}
int mystrncmp(const char *str1, const char *str2, size_t n)
{
//비교할 개수 n이 0이거나
//str1이 가리키는 문자가 종료 문자나 str1과 str2가 가리키는 문자가 다를 때까지 반복
for (n--; n&& *str1 && (*str1 == *str2); str1++, str2++)
{
n--;
}
return *str1 - *str2;
}