
사용할 모듈 포함문
import scipy as sp
from scipy import stats
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
import matplotlib.pyplot as plt
import numpy as np
import pandas as pdANOVA
Analysis of variance
두 개 이상의 그룹의 데이터가 있을 때 분산을 비교하는 검정 방법입니다.
ANOVA에는 일원분산분석, 이원분산분석, 다원분산분석, 다변량분산분석, 공분산분석이 있어요.
ANOVA의 분류는 대부분 독립변수와 종속변수의 개수에 따라서 구분합니다.
- 일원분산분석(one-way ANOVA) : 독립변수 요인 1개로 분석
- 이원분산분석(two-way ANOVA): 독립변수 요인 2개로 분석
- 다원분산분석(multi-way ANOVA): 독립변수 요인 n개로 분석
- 다변량분산분석(multi-variate ANOVA): 여러 개의 종속변수에 대해 분석할 때
- 공분산분석(ANCOVA) – 영향을 주는 요인이 있을 때
일원분산분석 (one-way ANOVA)
일원분산분석은 독립변수가 1개인데 비교할 그룹은 여러 개일 때 수행하는 ANOVA 검정 방법입니다.
예를 들어보기로 할게요.
다음 세 과목의 성적은 유의하게 차이가 있는지 유의 수준 0.05에서 검정하시오.
kor : 90,80,75,85,70,98,67,88,90,79,95
eng : 80,75,80,55,35,98,89,79,30,50,80,78
mat : 100,90,89,25,95,45,30,78,90,50,24,45,30
먼저 과목별 평균과 표준편차를 확인해 볼게요. (이는 일원분산분석에 필요한 절차는 아닙니다.)
kor = np.array([90,80,75,85,70,98,67,88,90,79,95])
eng = np.array([ 80,75,80,55,35,98,89,79,30,50,80,78])
mat = np.array([ 100,90,89,25,95,45,30,78,90,50,24,45,30])
print(f"국어 평균:{kor.mean():.2f} 표준편차:{kor.std(ddof=1):.2f}")
print(f"영어 평균:{eng.mean():.2f} 표준편차:{eng.std(ddof=1):.2f}")
print(f"수학 평균:{mat.mean():.2f} 표준편차:{mat.std(ddof=1):.2f}")[out]
국어 평균:83.36 표준편차:10.04
영어 평균:69.08 표준편차:21.44
수학 평균:60.85 표준편차:29.79세 과목의 성적을 정렬하여 비교해 보기로 할게요.(이 또한 일원분산분석에 필요한 절차는 아닙니다.)
kor.sort()
eng.sort()
mat.sort()
plt.plot(kor,'ro',label='korea')
plt.plot(eng,'gs',label='english')
plt.plot(mat,'b*',label='math')
plt.legend()
plt.show()[out]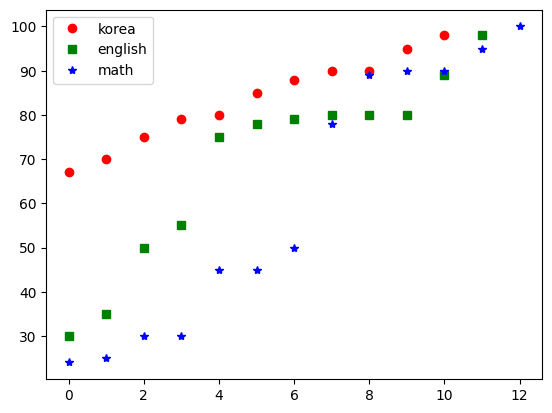
일원분산분석은 stats.f_oneway 함수를 이용합니다.
scipy.stats.f_oneway(*samples, axis=0)
scipy.stats.f_oneway
f_oneway의 반한 값은 F값과 p-value입니다.
p-value가 유의 수준보다 크면 귀무 가설을 채택하고 그렇지 않으면 기각합니다.
fv,pv = stats.f_oneway(kor,eng,mat)
print(f'f-value:{fv:.4f} p-value:{pv:.4f}')
if pv > 0.05:
print("귀무 가설을 채택한다. 세 과목은 통계적으로 유의하게 차이가 없다.")
else:
print("귀무 가설을 기각한다. 세 과목은 통계적으로 유의하게 차이가 있다.")[out]
f-value:3.0165 p-value:0.0626
귀무 가설을 채택한다. 세 과목은 통계적으로 유의하게 차이가 없다.이원분산분석(two-way ANOVA)
독립변수가 2개 이상이고 비교할 그룹이 여러 개일 때 수행하는 ANOVA 검정 방법입니다.
예를 들어 확인해 볼게요.
세 종류의 제품을 백화점에 입점하였을 때와 임접하지 않았을 때 매출액은 다음과 같다고 한다.
A: 80, 95
B: 120, 80
C: 130, 100
제품과 백화점 입점이 매출에 영향을 미치는지 유의 수준 0.05에서 이원분산분석하시오.
먼저 데이터를 DataFrame으로 표현할게요.
df = pd.DataFrame()
df['product'] =['a','a','b','b','b','c','c','c']
df['in_depart'] =[0,1,0,1,1,0,0,1]
df['sales'] =[80,70,70,100,90,40,40,50]최소제곱법(최소자승법) 모델로 fit한 후에 anova_lm 함수를 호출하면 결과를 얻을 수 있습니다.
statsmodels.formula.api.ols(formula, data, subset=
ols 메뉴얼 사이트None, drop_cols=None, *args, **kwargs)
statsmodels.stats.anova.anova_lm(*args, **kwargs)
anova_lm 메뉴얼 사이트
ols에 전달하는 formula에 C( )로 표현하는 것은 범주형 데이터를 의미합니다.
model = ols("sales ~ C(product) + C(in_depart)",df)
om = model.fit()
res = anova_lm(om)
print(res)[out]
df sum_sq mean_sq F PR(>F)
C(product) 2.0 2966.666667 1483.333333 14.833333 0.014116
C(in_depart) 1.0 183.333333 183.333333 1.833333 0.247178
Residual 4.0 400.000000 100.000000 NaN NaN결과에서 PR(>F) 부분을 보고 판별합니다.
C(product) 는 0.014116 이므로 유의 수준 0.05로 검정한다면 귀무 가설을 기각할 수 있는 값입니다. 따라서 제품 종류에 따라 판매액은 유의미하게 차이가 있다고 볼 수 있습니다.
C(in_depart)는 0.247178로 유의 수준 0.05로 검정한다면 귀무 가설을 채택할 수 있는 값입니다. 따라서 백화점 입점에 따라 판매액은 유의미하게 차이가 있다고 볼 수 없습니다.
다변량분산분석(MANOVA)
다변량분산분석은 종속 변수가 2개 이상일 때의 검정방법입니다.
예를 들어 볼게요.
a, b, c 세 종류의 제품이 백화점 입점 여부에 다른 매출액과 수익이 다음과 같다.
상품과 백화점 입점 여부는 매출액과 수익에 영향을 주는지 유의 수준 0.05에서 검정하시오.
상품: ‘a’,’a’,’b’,’b’,’b’,’c’,’c’,’c’
입점: 0,1,0,1,1,0,0,1
매출: 80,70,70,100,90,40,40,50
수익: 20,10,5,20,10,20,20,5
from statsmodels.multivariate.manova import MANOVA먼저 데이터를 DataFrame으로 만들게요.
df = pd.DataFrame()
df['product'] =['a','a','b','b','b','c','c','c']
df['in_depart'] =[0,1,0,1,1,0,0,1]
df['sales'] =[80,70,70,100,90,40,40,50]
df['profit'] =[20,10,5,20,10,20,20,5]classmethod MANOVA.from_formula(formula, data, subset=
메뉴얼 사이트None, drop_cols=None, *args, **kwargs)
MANOVA.mv_test(hypotheses=
메뉴얼 사이트None, skip_intercept_test=False
MANOVA 개체를 생성한 후 mv_test를 수행합니다.
maov = MANOVA.from_formula('C(product) + C(in_depart) ~ sales + profit', data=df)
print(maov.mv_test())[out]
Multivariate linear model
======================================================================================
--------------------------------------------------------------------------------------
Intercept Value Num DF Den DF F Value Pr > F
--------------------------------------------------------------------------------------
Wilks' lambda -0.0000 4.0000 2.0000 -32634779908482.3555 1.0000
Pillai's trace 1.0000 4.0000 2.0000 -32634779908482.3555 1.0000
Hotelling-Lawley trace -65269559816964.7109 4.0000 1.0000 -16317389954241.1777 1.0000
Roy's greatest root -65269559816964.7109 4.0000 2.0000 -32634779908482.3555 1.0000
--------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
sales Value Num DF Den DF F Value Pr > F
-------------------------------------------------------------------------------------------
Wilks' lambda 0.0480 3.0000 3.0000 19.8118 0.0176
Pillai's trace 0.9808 3.0000 3.0000 50.9528 0.0045
Hotelling-Lawley trace 19.2124 3.0000 3.0000 19.2124 0.0184
Roy's greatest root 19.1811 3.0000 3.0000 19.1811 0.0184
--------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
profit Value Num DF Den DF F Value Pr > F
-------------------------------------------------------------------------------------------
Wilks' lambda 0.3617 4.0000 2.0000 0.8822 0.5926
Pillai's trace 0.6409 4.0000 2.0000 0.8924 0.5892
Hotelling-Lawley trace 1.7570 4.0000 1.0000 0.4393 0.7942
Roy's greatest root 1.7528 4.0000 2.0000 0.8764 0.5946
======================================================================================MANOVA 개체의 mv_test 결과는 MultivariateTestResults 개체로 검정에 필요한 값은 summary_frame 속성의 ‘Pr > F’ 컬럼 값입니다.
maov = MANOVA.from_formula('C(product) + C(in_depart) ~ sales + profit', data=df)
res = maov.mv_test()
print(res.summary_frame['Pr > F'])[out]
Effect Statistic
Intercept Wilks' lambda 1.0
Pillai's trace 1.0
Hotelling-Lawley trace 1.0
Roy's greatest root 1.0
sales Wilks' lambda 0.017621
Pillai's trace 0.004507
Hotelling-Lawley trace 0.018402
Roy's greatest root 0.018445
profit Wilks' lambda 0.592632
Pillai's trace 0.589228
Hotelling-Lawley trace 0.794161
Roy's greatest root 0.594568
Name: Pr > F, dtype: object결과를 보면 판매액(sales)는 유의 수준 0.05보다 모두 작기 때문에 귀무 가설을 기각합니다. 이는 상품과 입점 여부에 따라 차이가 있다고 볼 수 있다는 것이죠.
수익(profit)은 유의 수준 0.05보다 모두 크기 때문에 귀무 가설을 채택합니다. 이는 상품과 입점 여부에 따라 차이가 있다고 볼 수 없다는 것입니다.
공분산분석(ANCOVA)
Analysis of covariance
공분산분석은 특정 인자가 종속 변수에 영향을 준다는 가정 하에 이를 고려하여 분석하는 검정 방법입니다.
파이썬에는 공분산분석에 관한 pingouin 모듈이 있습니다.
[설치]
!pip install pingouinfrom pingouin import ancovapingouin.ancova(data=None, dv=None, between=None, covar=None, effsize=’np2′)
pinguin.ancova
자세한 사항은 메뉴얼 사이트를 참고하세요.