위 문장의 뜻이 무엇일까요?
어느 나라 말인지 모르겠다고요. 위 문장은 일상에서 사용하는 문장이 아니라 암호화한 문장입니다. 네트워크 통신에서 스니핑 기술이 그리 어려운 것이 아니라서 암호화는 선택이 아닌 필수적인 요소라고 말해도 과언이 아닙니다.
이번에는 암호화에 관한 기초 상식을 살펴보려고 합니다.
암호화에서 제일 많이 사용하는 용어는 평문과 암호문입니다. 평문은 암호화하지 않은 상태의 문장을 의미하고 암호문은 암호화한 문장을 의미합니다.
치환암호
일정한 규칙에 따라 평문의 문자를 다른 문자로 치환하여 암호문을 만드는 암호화 방식입니다.
시저 암호(Caesar cipher, 카이사르 암호)
글자의 순서를 일정 간격으로 밀어서 치환하는 암호화 방식입니다.
시저가 군사적 목적으로 로마 문자를 그리스 문자로 치환하여 적들이 읽지 못하게 만들어 사용한 것에서 유래되었습니다.
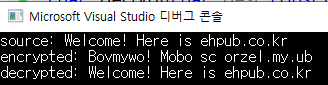
암호문: Bovmywo! Mobo sc orzel.my.ub
평문: Welcome! Here is ehpub.co.kr
위의 암호문 Bovmywo! Mobo sc orzel.my.ub 의 원래 평문은 Welcome! Here is ehpub.co.kr 입니다. 어떠한 규칙으로 이렇게 암호화를 하였을까요? 그리고 어떻게 하면 복호화할 수 있을까요?
암호화에 사용한 함수는 다음과 같습니다.
char *encrypt(char *dest, const char *src)
{
char *origin;
for (origin = dest; *src; dest++, src++)//종료 문자를 만날 때까지 반복
{
if (isupper(*src))//대문자일 때
{
*dest = (*src-'A' + 5) % 26 +'A';//5칸 밀기('A'->'F')
}
if (islower(*src))//소문자일 때
{
*dest = (*src -'a' + 10) % 26+ 'a';//10칸 밀기('a'->'k')
}
if (isdigit(*src))//숫자 문자일 때
{
*dest = (*src -'0' + 3) % 10 + '0';//3칸 밀기(0->3)
}
if (isalnum(*src) == 0)
{
*dest = *src;
}
}
*dest = '\0';
return origin;
}
대문자는 5칸 뒤로 밀기하였고 소문자는 뒤로 10칸 밀기하였습니다.
시저 암호 이동
그럼 복호화하려면 어떻게 해야 할까요? 암호화할 때 밀기한 만큼 당기기를 하면 되겠죠. 그런데 아스키 코드처럼 다른 문자가 섞여 있을 때 밀기한 만큼 당기기를 할 때 밀기를 이용합니다. 예를 들어 대문자일 때 5칸 밀기로 암호화하였다면 복호화할 때21칸 밀기를 하는 것이죠. 이와 같이 하면 5칸 당기기한 효과를 볼 수 있습니다.
char *decrypt(char *dest, const char *encryptstr)
{
char *origin;
for (origin = dest; *encryptstr; dest++, encryptstr++)//종료 문자를 만날 때까지 반복
{
if (isupper(*encryptstr))//대문자일 때
{
*dest = (*encryptstr - 'A'+21) % 26 + 'A';//21칸 밀기('F'->'A')
}
if (islower(*encryptstr))//소문자일 때
{
*dest = (*encryptstr - 'a'+16) % 26 + 'a';//16칸 밀기('k'->'a')
}
if (isdigit(*encryptstr))//숫자 문자일 때
{
*dest = (*encryptstr - '0'+7) % 10 + '0';//7칸 밀기(3->0)
}
if (isalnum(*encryptstr) == 0)
{
*dest = *encryptstr;
}
}
*dest = '\0';
return origin;
}
다음은 전체 소스 코드입니다.
//시저 암호(Caesar cipher, 카이사르 암호)
#include <stdio.h>
#include <ctype.h>
char *encrypt(char *dest, const char *src);
char *decrypt(char *dest, const char *encryptstr);
int main(void)
{
char source[100] = "Welcome! Here is ehpub.co.kr";
char en_str[100];
char de_str[100];
printf("source: %s\n", source);
encrypt(en_str, source);
printf("encrypted: %s\n", en_str);
decrypt(de_str, en_str);
printf("decrypted: %s\n", de_str);
return 0;
}
char *encrypt(char *dest, const char *src)
{
char *origin;
for (origin = dest; *src; dest++, src++)//종료 문자를 만날 때까지 반복
{
if (isupper(*src))//대문자일 때
{
*dest = (*src - 'A' + 5) % 26 + 'A';//5칸 밀기('A'->'F')
}
if (islower(*src))//소문자일 때
{
*dest = (*src - 'a' + 10) % 26 + 'a';//10칸 밀기('a'->'k')
}
if (isdigit(*src))//숫자 문자일 때
{
*dest = (*src - '0' + 3) % 10 + '0';//3칸 밀기(0->3)
}
if (isalnum(*src) == 0)
{
*dest = *src;
}
}
*dest = '\0';
return origin;
}
char *decrypt(char *dest, const char *encryptstr)
{
char *origin;
for (origin = dest; *encryptstr; dest++, encryptstr++)//종료 문자를 만날 때까지 반복
{
if (isupper(*encryptstr))//대문자일 때
{
*dest = (*encryptstr - 'A' + 21) % 26 + 'A';//21칸 밀기('F'->'A')
}
if (islower(*encryptstr))//소문자일 때
{
*dest = (*encryptstr - 'a' + 16) % 26 + 'a';//16칸 밀기('k'->'a')
}
if (isdigit(*encryptstr))//숫자 문자일 때
{
*dest = (*encryptstr - '0' + 7) % 10 + '0';//7칸 밀기(3->0)
}
if (isalnum(*encryptstr) == 0)
{
*dest = *encryptstr;
}
}
*dest = '\0';
return origin;
}