
안녕하세요. 언제나휴일입니다.
앞에서 우리는 웹 페이지를 수집하는 로봇과 형태소 분석기를 만들었습니다.
이제 웹 검색 엔진을 만들어 볼게요.
1. 시멘틱 검색 엔진 소개
2000년 무렵에 케이블 인터넷과 ADSL기술을 도입하면서 초고속 인터넷을 보급하던 때만 하더라도 웹 사이트에 글을 포스팅하는 것은 업체나 기관에서 할 일이라 생각했지요.
그런데 지금은 SNS의 등장을 비롯하여 많은 곳에서 All IP 시대로 가기 위한 준비를 하면서 웹 사이트를 방문하는 지식 소비자와 웹 사이트를 구축하고 지식 포워딩하는 지식 공급자가 뚜렷하게 나눌 수 없는 프로슈머 형태를 지니고 있습니다.
시멘틱 검색 엔진이라는 것이 세상에 모습을 드러낼 때만 해도 포털 사이트에서만 사용할 기술처럼 생각했습니다. 그리고 새로 포스팅하는 자료의 양이 지금에 비해 적어 높은 수준의 기술을 요구하지 않았었죠. 하지만 지금은 일반 사용자들도 자신의 블로그나 SNS에 일상과 자신의 취미 생활 및 기술을 포스팅하고 있어 압도적인 자료를 새로 생산하고 있으며 이에 높은 기술 수준의 검색 엔진을 요구하고 있습니다.
자료가 많지 않던 시절에는 과도히 많은 자료가 생기면 오히려 필요한 자료를 찾기 힘들다는 논리를 펼치던 시절도 있었습니다. 하지만 지금에 와서는 이들 자료를 효과적으로 통계를 내고 분석하여 필요한 정보를 추출하는 기술의 발달로 자료가 축적되고 변화하는 모습에 따라 지식에도 생명이 있음을 인지하는 수준에 도달하였습니다.
이제 시멘틱 검색 엔진은 포탈 사이트에서만 필요한 기술이 아닌 수 많은 서비스에서 사용해야 할 기술로 변하고 있습니다. 여러분들이 이 책을 통해 시멘틱 검색 엔진을 만들기 위한 기본적인 기술을 익혀 다양한 분야에 활용할 수 있었으면 합니다.
자료가 모이고 이를 통계 및 분석을 통해 지식에 생명을 불어 넣듯이 우리의 기술이 모여 삶의 질 향상에 이바지할 수 있기를 기원합니다.
최근 인터넷의 발달로 다양한 정보를 웹을 통해 얻습니다. 특히 개인 블로그 및 커뮤니티 사이트, 소셜 사이트의 증가로 정보 공급자와 정보 사용자의 경계가 사라져가고 있습니다.
이처럼 다양한 형태의 방대한 자료가 웹 상에 만들어지고 있어 효과적인 검색을 위한 검색 엔진들을 연구하고 만들어지고 있습니다. 특히 검색 엔진은 기존의 포털 사이트에서 제공하는 서비스였지만 소셜 사이트 및 다양한 정보 서비스를 위해 필요한 곳이 많아집니다.
이 책에서는 기존 웹 검색 엔진을 만드는 전체 공정을 순서대로 하나 하나 설명하고 궁극적으로 서비스 목적에 맞는 검색 엔진을 만들 수 있게 할 것입니다.
여러분도 잘 아시는 것처럼 검색 엔진은 사용자가 원하는 정보를 검색해 주는 도구나 서비스를 말합니다. 특히 웹 검색 엔진은 웹 상에 게시되어 있는 수 많은 웹 페이지의 내용에서 원하는 정보를 검색해 주는 엔진입니다.
이러한 검색 엔진은 방대한 자료에서 빠르고 정확하게 원하는 정보를 검색하는 것이 중요합니다. 만약 자료의 양이 많지 않다면 굳이 고사양의 검색 엔진은 필요하지 않을 것입니다.
따라서 검색 엔진은 방대한 자료를 수집하는 작업이 필요합니다. 그리고 수집한 자료를 분석하는 작업, 분석한 결과를 검색하기 쉽게 가공하는 작업, 검색 작업과 검색한 결과를 선별 및 순위를 정하는 등의 작업이 필요합니다.
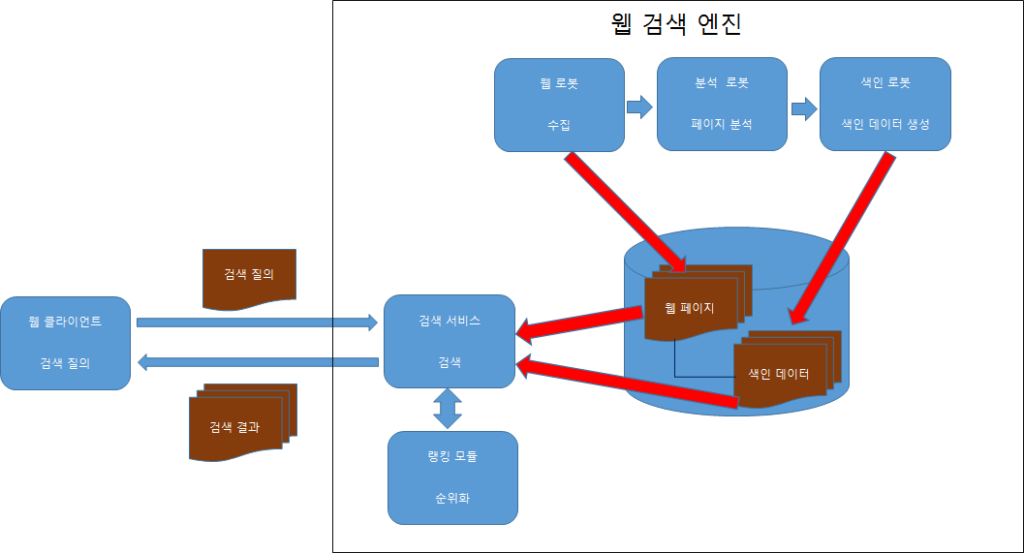
웹 검색 엔진의 구성을 살펴보면 게시한 웹 페이지를 수집하는 웹 로봇과 수집한 웹 페이지 내용을 분석하는 분석 로봇, 분석한 결과를 색인하는 색인 로봇, 검색 요청을 받아 색인 자료를 통해 검색 결과를 얻어오는 검색 엔진으로 구성합니다. 그리고 검색 결과를 순위화하는 랭킹 모듈 등을 추가로 구성하여 품질 수준을 높일 수 있습니다.
* 나만의 웹 검색 엔진 만들기(예전에 집필한 책)에서 발췌*
2. TF-IDF (Term Frequency – Inverse Document Frequency)
수 많은 자료 중에서 원하는 결과를 검색하면 검색 결과도 많을 수 있습니다. 이 때 사용자는 검색 결과에서 다시 원하는 결과를 검색하는 비용이 들 수 있습니다.
자료의 양이 많아지면서 검색 엔진도 보다 효과적으로 검색 결과를 제공하기 위해 똑똑해지고 있습니다. 이를 위해 시멘틱 처리의 알고리즘이 필요한데 여기서 다루는 랭커는 시멘틱 처리를 하는 기본적인 알고리즘을 사용할 것입니다.
랭커에서 순위를 매기는 방법은 다양한데 여기에서는 TF IDF 방식을 사용할 것입니다.
TF는 Term Frequency의 약어로 특정 단어가 얼마나 자주 나오는지에 관한 값입니다. 따라서 문서에 특정 단어의 참조 개수를 문서의 전체 형태소 개수로 나눈 값입니다.
IDF는 Inverse Document Frequecy의 약어로 특정 단어를 포함하는 문서가 얼마나 많은지에 따라 희귀성을 구하는 값입니다. DF값은 먼저 특정 단어를 포함하는 문서 개수를 전체 문서 개수로 나는 값입니다. 그리고 IDF값은 이를 역수를 취한 값인데 많은 곳에서는 이를 다시 log를 취해서 사용하고 있습니다.
따라서 TF IDF 방식은 문서에 특정 단어가 나오는 빈도수인 TF로 해당 문서에 특정 단어의 중요도를 점검하고 IDF를 통해 전체 문서에서 해당 단어를 포함하는 문서의 빈도로 희귀성을 계산하는 것입니다.
목적에 따라 검색하는 사용자의 연령이나 나이, 지역, 성별 등과 비슷한 이가 작성한 글에 가중치를 두어 랭커를 만들며 보다 효과적인 랭커를 만들 수 있습니다. 물론 목적에 맞는 인자를 선별하고 적당한 가중치를 찾는 작업이 필요한데 이러한 부분은 관련 논문을 참고할 수 있다면 이를 활용하는 것이 좋은 방법일 수 있습니다.
* 나만의 웹 검색 엔진 만들기(예전에 집필한 책)에서 발췌*