
이번에는 간선의 비용이 있는 그래프에서 최단 거리를 찾는 알고리즘 중에 하나인 다익스트라 알고리즘을 살펴 보아요.
다익스트라 알고리즘은 출발 정점에서 가까운 경로 순으로 보관하는 우선 순위 큐와 출발 정점에서 특정 정점까지 최단 경로 후보들을 보관하는 후보 테이블을 이용하는 알고리즘입니다. 참고로 벨만 포드 알고리즘은 간선의 비용이 음수일 때도 적용할 수 있는 알고리즘이며 나머지는 다익스트라와 같습니다.
제일 먼저 출발 정점에서 인점한 정점을 방문하는 다음 경험 목록을 구합니다. 그리고 마지막 정점까지 가는 경로가 후보 테이블에 있는지 확인합니다. 만약 후보 테이블에 있는 경로가 새로운 경로보다 비용이 많으면 새로운 경로로 교체합니다. 처음 마지막 정점이 방문하였을 때는 후보 테이블에 추가합니다. 그리고 교체하거나 추가하였을 때는 우선 순위 큐에도 보관합니다. 큐가 빌 때까지 방문하면 한 정점에서 다른 모든 정점에 갈 수 있는 최단 경로를 구할 수 있습니다. 물론 특정 정점까지의 최단 경로를 찾는다면 중간에 경로 찾기를 멈추는 로직이 필요하겠죠.
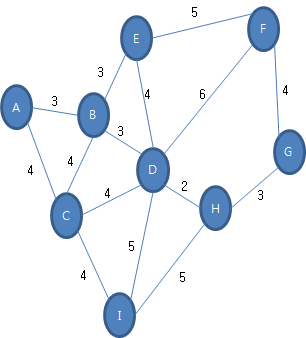
다음의 그래프에서 보다 구체적으로 동작 원리를 알아봅시다.
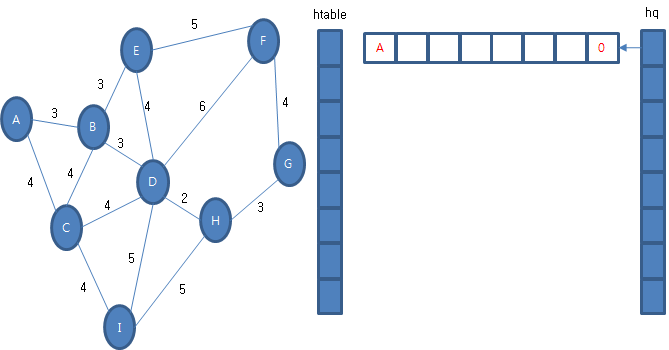
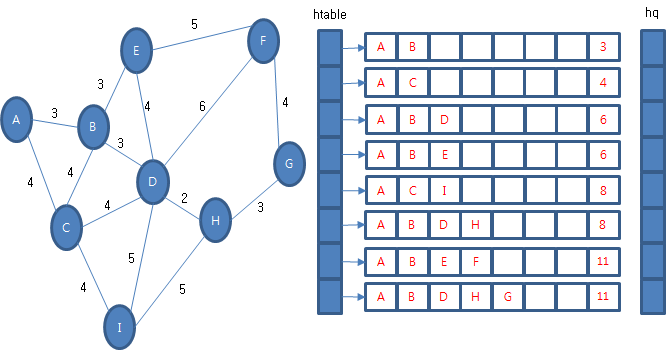
A 정점에서 다른 정점드로 가는 최단 경로를 찾는 과정을예로 설명하기로 할게요. 초기에는 A 정점을 방문한 경험을 우선 순위 큐에 보관한 상태에서 출발합니다.
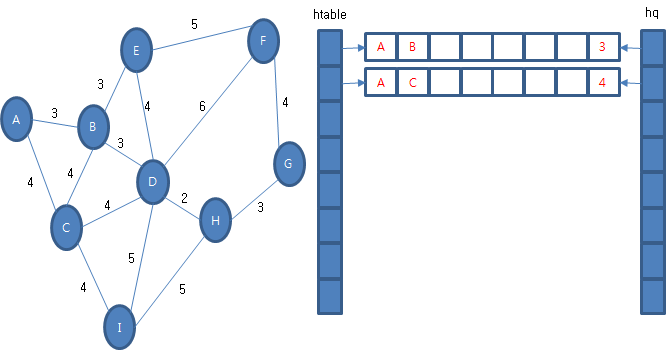
우선 순위 큐에서 경험 정보를 꺼내옵니다. 그리고 다음 경험 정보를 조사합니다. (A, B, 3)과 (A, C, 4)가 있겠죠. 둘 다 후보 테이블에 없기 때문에 후보 테이블에도 보관하고 우선 순위 큐에도 보관합니다.
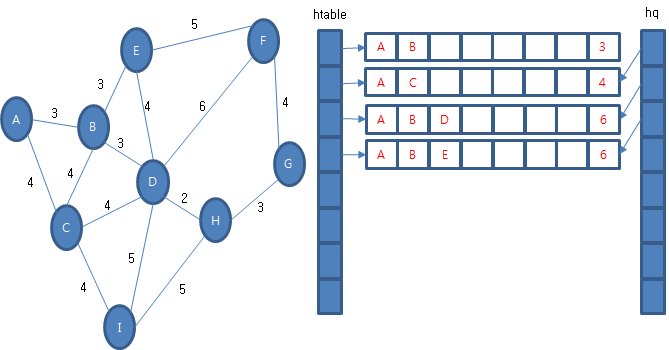
그리고 우선 순위 큐에서 경험 정보를 꺼내옵니다. 꺼내온 경험 정보 (A, B, 3)에서 갈 수 있는 다음 경험 정보를 조사합니다. (A, B, D, 6), (A, B, E, 6), (A, B, C, 7)가 있습니다. (A, B, D, 6)과 (A, B, E, 6)의 마지막 정점은 후보 테이블에 없으므로 후보 테이블과 우선 순위 큐에 보관합니다. 하지만 (A, B, C, 7)은 이미 후보 테이블에 있습니다. 그리고 후보 테이블에 있는 전체 비용이 작기 때문에 교체나 우선 순위 큐에 보관하지 않습니다.
다시 우선 순위 큐에서 경험 정보를 꺼내옵니다. 꺼내온 경험 정보 (A, C, 4)에서 갈 수 있는 다음 경험 정보를 조사합니다. (A, C, B, 8), (A, C, D, 8), (A, C, I, 8)이 있습니다. (A, C, B, 8)와 (A, C, D, 8)의 마지막 정점은 후보 테이블에 이미 있습니다. 그리고 둘 다 후보 테이블에 있는 전체 비용이 작기 때문에 교체나 우선 순위 큐에 보관하지 않습니다. (A, C, I, 8)의 마지막 정점은 처음 방문하는 것이므로 후보 테이블과 우선 순위 큐에 보관합니다.
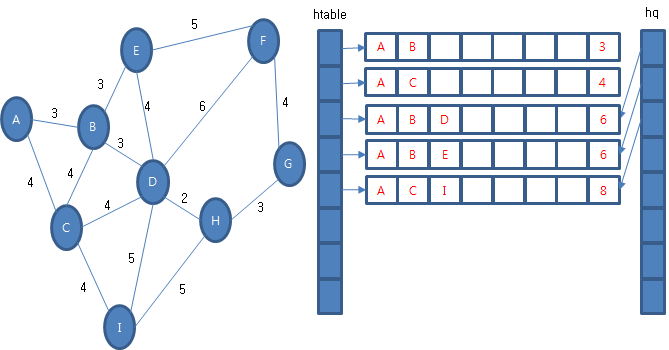
다시 우선 순위 큐에서 경험 정보를 꺼내옵니다. 꺼내 온 경험 정보 (A, B, D, 6)에서 갈 수 있는 다음 경험 정보를 조사합니다. (A, B, D, C, 10), (A, B, D, E, 10), (A, B, D, F, 12), (A, B, D, H, 8), (A, B, D, I, 11) 이 있습니다. 이 중에서 (A, B, D, C, 10), (A, B, D, E, 10), (A, B, D, I, 11)은 마지막 정점이 후보 테이블에 있고 후보 테이블에 비용이 작기 때문에 교체나 우선 순위 큐에 보관하지 않습니다. (A, B, D, F, 12), (A, B, D, H, 8)의 마지막 정점은 처음 방문하는 것이므로 후보 테이블과 우선 순위 큐에 보관합니다.
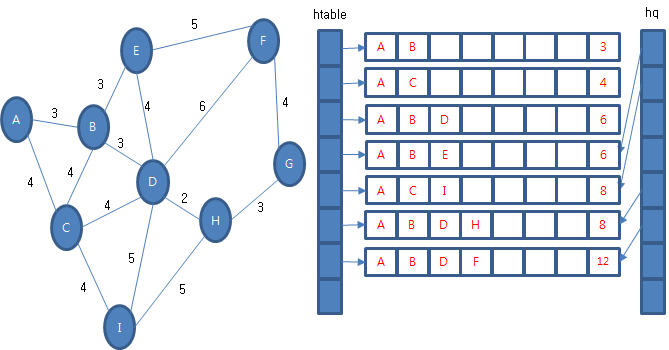
다시 우선 순위 큐에서 경험 정보를 꺼내옵니다. 꺼내 온 경험 정보 (A, B, E, 6)에서 갈 수 있는 다음 경험 정보를 조사합니다. (A, B, E, D, 10), (A, B, E, F, 11)이 있습니다. (A, B, E, D, 10)의 마지막 정점은 후보 테이블에 있고 전체 비용도 더 작기 때문에 교체나 우선 순위 큐에 보관하지 않습니다. 그런데 (A, B, E, F, 11)의 마지막 정점은 후보 테이블에 있지만 전체 비용은 새로운 것이 더 작으므로 후보 테이블에 있는 것을 지우고 새로운 것으로 교체합니다. 그리고 우선 순위 큐에도 보관합니다.
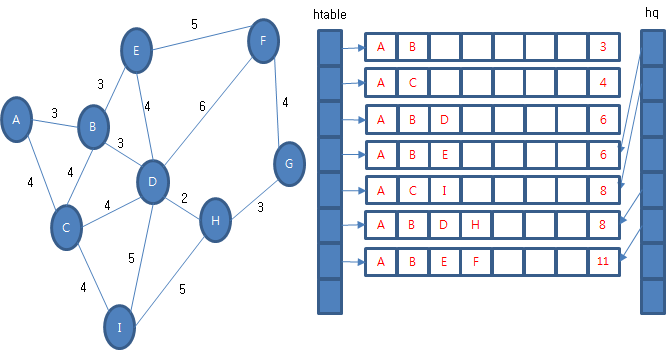
다시 우선 순위 큐에서 경험 정보를 꺼내옵니다. 꺼내 온 경험 정보 (A, C, I, 8)에서 갈 수 있는 다음 경험 정보를 조사합니다. (A, C, I, D, 13), (A, C, I, H, 13)이 있습니다. 둘 다 마지막 정점이 후보 테이블에 있고 후보 테이블에 비용이 작기 때문에 교체나 우선 순위 큐에 보관하지 않습니다.
다시 우선 순위 큐에서 경험 정보를 꺼내옵니다. 꺼내 온 경험 정보 (A, B, D, H, 8)에서 갈 수 있는 다음 경험 정보를 조사합니다. (A, B, D, H, I, 13), (A, B, D, H, G, 11)이 있습니다. (A, B, D, H, I, 13)은 마지막 정점이 후보 테이블에 있고 후보 테이블에 비용이 작기 때문에 교체나 우선 순위 큐에 보관하지 않습니다. (A, B, D, H, G, 11)의 마지막 정점은 처음 방문한 것이므로 후보 테이블과 우선 순위 큐에 보관합니다.
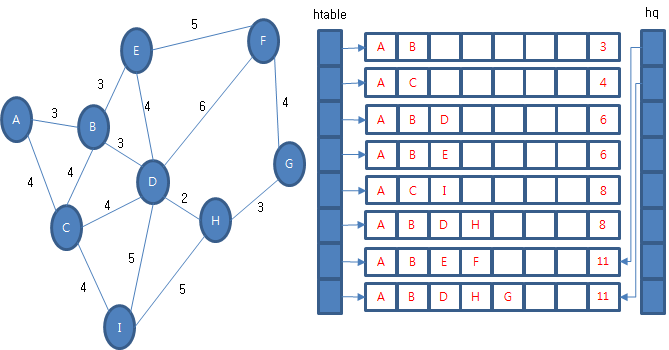
큐가 빌 때까지 반복하면 정점 A에서 모든 정점으로 갈 수 있는 최단 경로가 후보 테이블에 남습니다.
{kind=link}