
안녕하세요. 언제나 휴일에 언휴예요.
이번 강의는 문자 형식 char와 ASCII 코드에 관해 다루기로 할게요.
1. ASCII 코드와 char 형식 크기 2. 숫자 문자, 소문자, 대문자 ASCII 코드 값 확인 3. 문자 리터럴 4. char 형식의 한계 5. ASCII 코드
1. ASCII 코드와 char 형식 크기
C언어는 미국에서 만들었죠.
C언어의 문자 표현은 미국 표준 문자인 ASCII 코드를 표현하도록 만들었어요.
ASCII , American Standard Code for Information Interchange
C언어에서 문자를 표현할 때 char 형식을 사용합니다.
char 형식은 미국의 표준 문자인 ASCII 코드를 표현할 수 있는 크기로 설계한 거예요.
영문 알파벳 소문자, 대문자, 숫자 문자 및 기타 문자를 포함해도 1바이트면 표현이 가능하죠.
char의 크기가 1바이트인 이유도 여기에 있어요.
지난 강의(정수 형식과 표현 범위)에 char 형식 크기가 1byte이고 -128~127까지 표현할 수 있다는 것을 확인했었죠.
printf("sizeof(char):%d bytes\n", sizeof(char));
2. 숫자 문자, 소문자, 대문자 ASCII 코드 값 확인
C언어에서 문자 표현은 단일 콤마 사이에 문자를 표현합니다.
여기서 문자 표현은 문자 한 개를 표현하는 것을 말합니다.
먼저 숫자 문자 ‘0’과 대문자 ‘A’, 소문자 ‘a’가 ASCII 코드 값이 얼마인지 확인합시다.
#include //표준 입출력 헤더
int main()
{
printf("%c:%d %#x\n", '0', '0', '0');
printf("%c:%d %#x\n", 'A', 'A','A');
printf("%c:%d %#x\n", 'a', 'a','a');
return 0;
}
실행 결과는 다음과 같아요.
0:48 0x30 A:65 0x41 a:97 0x61
결과를 보면 숫자 문자 ‘0’은 16진수로 0x30입니다. ( 이진수로 0011 0000)
결과를 보면 대문자 ‘A’는 16진수로 0x41입니다. ( 이진수로 0100 0001)
결과를 보면 소문자 ‘a’는 16진수로 0x61입니다. ( 이진수로 0110 0001)
숫자 문자 ‘1’~’9’의 ASCII 코드 값은 0x31~0x39입니다.
영문 알파벳의 ASCII 코드 값도 ‘A’와 ‘a’에서 순차적으로 부여했어요.
#include //표준 입출력 헤더
int main()
{
printf("%c:%d %#x\n", '0', '0', '0'); //0011 0000
printf("%c:%d %#x\n", '1', '1', '1'); //0011 0001
printf("%c:%d %#x\n", 'A', 'A','A'); //0100 0001
printf("%c:%d %#x\n", 'B', 'B', 'B'); //0100 0010
printf("%c:%d %#x\n", 'a', 'a','a'); //0110 0001
printf("%c:%d %#x\n", 'b', 'b', 'b'); //0110 0010
return 0;
}
다음은 실행한 결과입니다.
0:48 0x30 1:49 0x31 A:65 0x41 B:66 0x42 a:97 0x61 b:98 0x62
3. 문자 리터럴
개발자는 ASCII 코드 값을 기억하지 않아도 프로그램을 작성하는 데 지장이 없어요.
이를 위해 단일 콤마 사이에 문자를 표현하는 문자 리터럴을 제공하는 것이죠.
이전 강의에서 확인했듯이 문자 리터럴 표현의 크기는 1바이트가 아닌 4바이트입니다.
이것을 모른다고 프로그래밍에 지장을 주는 것은 1도 없습니다.
*확장자 cpp로 만들어서 확인하면 1바이트입니다. C++에서는 문자 리터럴 표현은 char로 취급하며 1바이트입니다.*
#include //표준 입출력 헤더
int main()
{
printf("sizeof('a'):%d bytes\n",sizeof('a'));
return 0;
}
실행 결과를 확인하면 1 bytes가 아닌 4 bytes인 것을 알 수 있어요.
4bytes
문자 리터럴 표현은 ASCII 코드 값과 같은 표현입니다.
개발자가 ASCII 코드 값을 기억하지 않아도 지장없게 하기 위해 제공하는 것이죠.
#include //표준 입출력 헤더
int main()
{
char ch = 97;
char ch2 = 'a';
printf("%c\n", ch);
printf("%c\n", 97);
printf("%c\n", ch2);
return 0;
}
실행 결과를 보면 세 가지 표현은 같다는 것을 알 수 있어요.
a a a
4. char 형식의 한계
한글의 문자는 256개를 초과합니다.
이는 char 형식으로 한글 문자를 표현하지 못 합니다.
#include
int main()
{
char ch = 'ㄱ';
printf("%c\n", ch);
return 0;
}
실행 결과를 보면 엉뚱한 문자를 출력하고 있어요.
?
우연하게 모르겠다는 ‘?’문자를 출력하고 있네요.
C언어의 char 형식은 영문자 외에 다른 문자를 사용하는 곳에서 사용이 불편합니다.
C언어 표준은 미국 표준 기구인 ANSI에서 제시했었죠. 하지만 지금은 국제 표준 기구 ISO에서 제시하고 있어요.
그리고 char 형식의 단점을 극복하기 위해 wchar_t 형식을 제공하는 것을 권고하였습니다.
이번 강의는 이러한 문제점이 있고 이를 해결하기 위해 wchar_t이 나왔다는 것까지 소개하기로 할게요.
5. ASCII 코드
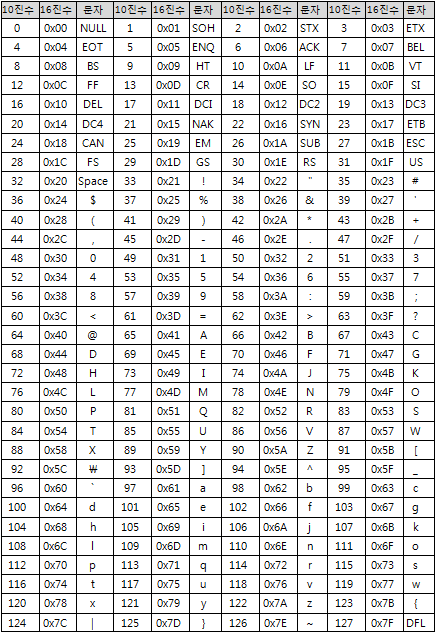
아스키 코드에는 문자외에도 데이터 전송 시작, 끝 등을 나타내는 제어 신호도 있어요.
아스키 코드는 원래 하드웨어와 하드웨어, 하드웨어와 운영체제 사이에 주고 받는 신호를 약속한 것이예요.
이러한 이유로 문자가 아닌 제어 신호도 포함하고 있어요.
다음은 아스키 코드의 특수 문자와 제어 신호들이예요.
여러분들이 C언어를 배우는 과정에서 이를 알아야 할 필요는 없으니 가볍게 참고만 하세요.
NUL : NULL SOH : 데이터 전송 시작 STX : 본문 시작, ETX: 본문 종료, EOT: 전송 종료, ETB: 전송 블록 종료 ENQ: 응답 요구, ACK: 긍정 응답 BEL: 경고음 BS: Back Space HT:수평 탭, LF: 개행, VT: 수직 탭, FF: 다음 페이지, CR:Carrige Return SO: 확장 문자 시작, SI:확장 문자 종료 DFL: 전송 제어 확장 DC1: Device Control 1, DC2: Device Control 2 DC3: Device Control 3, DC4: Device Control 4 NAK: 부정 응답, SYN: Synchronous Idle, CAN: 취소 EM: 매체 종료 SUB: 치환 ESC: Escape FS: 파일 경계, GS: 그룹 경계, RS: 레코드 경계, US: 장치 경계