
데이터를 분석할 때 제일 먼저 대푯값을 확인하죠.
다음으로 어떤 작업을 주로 하시나요?
데이터를 구성하는 변수 사이의 관계를 파악하는 것은 분석의 가치를 높이는 일이죠.
변수 사이의 관계를 얘기할 때 가장 기초적인 것이 공분산과 상관계수입니다.
공분산(Covariance)
공분산은 두 개의 변수가 선형 상관성이 있는지 파악하는 수치입니다.
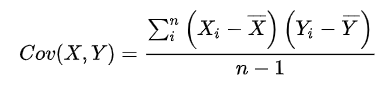
공분산 값이 0보다 크면 하나의 값이 상승할 때 다른 변수도 상승하는 경향을 보입니다.
공분산 값이 0보다 작으면 하나의 값이 상승할 때 다른 변수는 하강하는 경향을 보이는 것이죠.
[Code]
import numpy as np
def cov(x,y): #표본공분산
dx = x - x.mean()
dy = y - y.mean()
return np.dot(dx,dy)/(len(x)-1)
def cov2(x,y): #모공분산
dx = x - x.mean()
dy = y - y.mean()
return np.dot(dx,dy)/(len(x))사이킷런의 datasets에서 제공하는 iris 데이터에서 꽃잎의 길이와 너비 사이의 공분산을 구해봅시다.
먼저 사이킷런의 iris 데이터를 로드합시다.
[Code]
import sklearn.datasets
origin_data = sklearn.datasets.load_iris()
print(origin_data)출력 결과를 보면 ‘data’에 4개의 변수로 구성한 목록을 요소로 하는 2차원 배열로 구성하고 있습니다.
‘target’에는 0, 1, 2 값으로 data의 각 요소 배열이 어떤 품종(setosa, versicolor, virginica)인지 나타냅니다.
‘feature_names’에는 요소 배열의 4개의 변수(꽃받침 길이, 너비, 꽃잎 길이, 너비)가 무엇인지 나타냅니다.
[Out]
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
......중략.......
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]]), 'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]), 'frame': None, 'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10'),
...중략...,
'feature_names': ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'], 'filename': 'iris.csv', 'data_module': 'sklearn.datasets.data'}‘data’ 부분에서 꽃잎의 길이와 너비 부분을 추출할게요.
[Code]
data = origin_data['data']
petal_length = data[:,2]
petal_width = data[:,3]
print(petal_length)
print(petal_width)꽃잎의 길이는 1~7 정도의 값을 갖는 것을 알 수 있습니다.
꽃잎의 너비는 0.1~2.5 정도의 값을 갖는 것을 알 수 있습니다.
[out]
[1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 1.5 1.6 1.4 1.1 1.2 1.5 1.3 1.4
1.7 1.5 1.7 1.5 1. 1.7 1.9 1.6 1.6 1.5 1.4 1.6 1.6 1.5 1.5 1.4 1.5 1.2
1.3 1.4 1.3 1.5 1.3 1.3 1.3 1.6 1.9 1.4 1.6 1.4 1.5 1.4 4.7 4.5 4.9 4.
4.6 4.5 4.7 3.3 4.6 3.9 3.5 4.2 4. 4.7 3.6 4.4 4.5 4.1 4.5 3.9 4.8 4.
4.9 4.7 4.3 4.4 4.8 5. 4.5 3.5 3.8 3.7 3.9 5.1 4.5 4.5 4.7 4.4 4.1 4.
4.4 4.6 4. 3.3 4.2 4.2 4.2 4.3 3. 4.1 6. 5.1 5.9 5.6 5.8 6.6 4.5 6.3
5.8 6.1 5.1 5.3 5.5 5. 5.1 5.3 5.5 6.7 6.9 5. 5.7 4.9 6.7 4.9 5.7 6.
4.8 4.9 5.6 5.8 6.1 6.4 5.6 5.1 5.6 6.1 5.6 5.5 4.8 5.4 5.6 5.1 5.1 5.9
5.7 5.2 5. 5.2 5.4 5.1]
[0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 0.2 0.2 0.1 0.1 0.2 0.4 0.4 0.3
0.3 0.3 0.2 0.4 0.2 0.5 0.2 0.2 0.4 0.2 0.2 0.2 0.2 0.4 0.1 0.2 0.2 0.2
0.2 0.1 0.2 0.2 0.3 0.3 0.2 0.6 0.4 0.3 0.2 0.2 0.2 0.2 1.4 1.5 1.5 1.3
1.5 1.3 1.6 1. 1.3 1.4 1. 1.5 1. 1.4 1.3 1.4 1.5 1. 1.5 1.1 1.8 1.3
1.5 1.2 1.3 1.4 1.4 1.7 1.5 1. 1.1 1. 1.2 1.6 1.5 1.6 1.5 1.3 1.3 1.3
1.2 1.4 1.2 1. 1.3 1.2 1.3 1.3 1.1 1.3 2.5 1.9 2.1 1.8 2.2 2.1 1.7 1.8
1.8 2.5 2. 1.9 2.1 2. 2.4 2.3 1.8 2.2 2.3 1.5 2.3 2. 2. 1.8 2.1 1.8
1.8 1.8 2.1 1.6 1.9 2. 2.2 1.5 1.4 2.3 2.4 1.8 1.8 2.1 2.4 2.3 1.9 2.3
2.5 2.3 1.9 2. 2.3 1.8]꽃잎의 길이와 너비를 도면으로 그려 대략적인 관계를 눈으로 확인해 봅시다.
[Code]
import matplotlib.pyplot as plt
plt.figure(figsize=(4,4))
plt.plot(petal_length, petal_width,'.')
plt.xlabel('petal length (cm)')
plt.ylabel('petal width (cm)')
plt.xlim(0,8)
plt.ylim(0,8)
plt.show()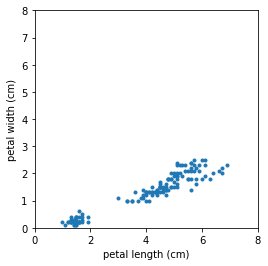
앞에서 작성한 cov 함수를 호출하여 표본 공분산 값을 확인합시다.
[Code]
print("공분산(petal length, petal width) = ",cov(petal_length, petal_width))[Out]
공분산(petal length, petal width) = 1.2956093959731547numpy에서는 cov 함수를 제공하여 공분산을 확인할 수 있습니다.
[Code]
print(np.cov(petal_length, petal_width))출력 값은 2X2 배열로 공분산(꽃잎의 길이, 꽃잎의 길이), 공분산(꽃잎의 길이, 꽃잎의 너비), 공분산(꽃잎의 너비, 꽃잎의 길이), 공분산(꽃잎의 너비, 꽃잎의 너비) 값입니다.
[Out]
[[3.11627785 1.2956094 ]
[1.2956094 0.58100626]]만약 꽃잎의 길이와 너비 사이의 공분산을 구하려면 다음처럼 구할 수 있어요.
[Code]
print("공분산(petal length, petal width) = ",np.cov(petal_length, petal_width)[0][1])결과를 보면 직접 구현한 cov 함수를 호출한 결과와 같은 것을 알 수 있어요.
[Out]
공분산(petal length, petal width) = 1.2956093959731547공분산 값을 통해 꽃잎의 길이와 너비는 양의 공분산을 갖는 것을 알 수 있어요. 이것은 도표로 확인한 결과와 같습니다.
상관계수
하지만 공분산 값은 측정 단위의 크기에 따라 달라지기 때문에 상관분석에는 부적절합니다.
상관분석에는 상관 관계의 정도를 나타내는 상관계수를 사용하는 것이 바람직합니다.
상관계수는 -1~1 사이의 값으로 절대값이 1에 가까울 수록 관계가 강하고 0에 가까울 수록 관계가 약한 것을 의미합니다.
양수일 때는 하나의 변수가 상승할 때 다른 변수도 상승하는 경향을 지님을 의미합니다.
음수일 때는 하나의 변수가 상승할 때 다른 변수는 하강하는 경향을 지님을 의미합니다.
다음은 가장 많이 사용하는 피어슨 상관계수입니다.
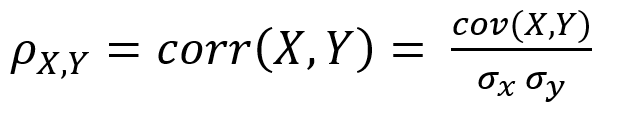
파이썬 코드로 작성하면 다음처럼 구현할 수 있겠죠.
*모공분산을 사용합니다.*
[Code]
def correlation(x,y):
std_x = x.std()
std_y = y.std()
if std_x>0 and std_y>0:
return cov2(x,y)/std_x/std_y
else:
raise ZeroDivisionError()꽃잎의 길이와 너비 사이의 피어슨 상관계수를 구해봅시다.
[Code]
print("상관계수(petal_length, petal_width) = ",correlation(petal_length, petal_width))[Out]
상관계수(petal_length, petal_width) = 0.9628654314027963Pandas의 DataFrame과 Series에는 corr 메서드를 제공합니다.
먼저 DataFrame의 corr 메서드를 호출하여 확인해 봅시다.
[Code]
df = pd.DataFrame({'petal_length':petal_length, 'petal_width':petal_width})
print(df.corr())[Out]
petal_length petal_width
petal_length 1.000000 0.962865
petal_width 0.962865 1.000000이번에는 Series의 corr 메서드를 호출하여 확인해 봅시다.
*DataFrame의 특정 컬럼을 선택한 형식은 Series입니다.*
[Code]
print(df['petal_length'].corr(df['petal_width']))[Out]
0.9628654314027961