
사용할 모듈 포함문
from sklearn.linear_model import LogisticRegression #로지스틱 회귀
from sklearn.linear_model import LinearRegression #선형 회귀
from sklearn.datasets import load_iris #붓꽃 데이터 로드
from sklearn.model_selection import train_test_split #학습 및 테스트 데이터 분리
from sklearn.metrics import accuracy_score #적합도(분류)
from sklearn.model_selection import cross_val_score #교차 검증 점수
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt로지스틱 회귀 (Logistic Regression)
로지스틱 회귀는 이름만 보면 회귀 작업에서 사용하는 모델로 보입니다.
하지만 로지스틱 회귀는 분류 작업에서 사용하는 분류 모델입니다.
로지스틱 회귀는 선형 관계를 분석하여 사건 발생 가능성을 예측하는 통계 기법입니다.
로지스틱 회귀에서는 선형 회귀의 결과를 로지스틱 함수를 통해 0에서 1 사이의 값으로 변환합니다.
0은 사건이 발생할 확률이 0%라는 의미로 해석하며 1은 100%로 해석할 수 있습니다.
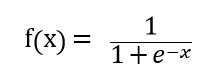
로지스틱 함수의 또 다른 이름은 sigmoid 함수입니다.
def sigmoid(self,x):
return 1/(1+np.exp(-x))다음은 로지스틱 함수(sigmoid 함수)를 시각화 한 코드입니다.
data = np.arange(-7,7,0.2)
target = [sigmoid(x) for x in data]
plt.plot(data,target)
plt.axvline(x=0,color='k')
plt.axhline(y=0,color='k')
plt.axhline(y=0.5,color='k',linestyle=':')
plt.axhline(y=1,color='k',linestyle=':')
plt.ylim(0,1.1)
plt.title("sigmoid function")
plt.show()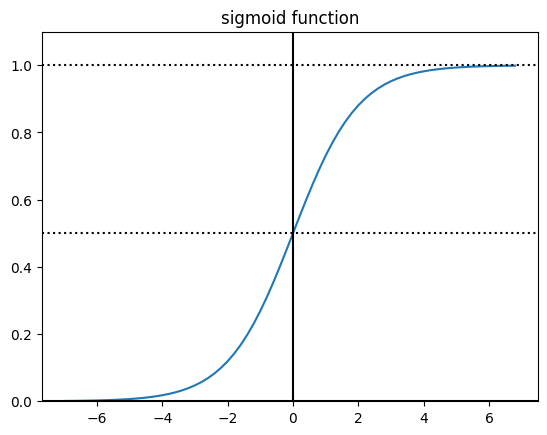
로지스틱 회귀 모델 사용 예
예를 통해 로지스틱 회귀 모델을 사용해 봅시다.
class sklearn.linear_model.LogisticRegression(penalty=’l2′, *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’lbfgs’, max_iter=100, multi_class=’auto’, verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
LogisticRegression 메뉴얼 사이트
여기에서는 붓꽃 데이터를 통해 품종을 분류하는 작업을 해 볼게요.
먼저 붓꽃 데이터를 얻어와서 독립 변수와 종속 변수를 선언합니다.
iris = load_iris()
data = iris.data
target = iris.target학습 데이터와 테스트 데이터로 분리할게요. (이번 작업에서 검증은 생략하겠습니다.)
x_train,x_test, y_train,y_test = train_test_split(data,target)로지스틱 회귀 모델을 생성하여 학습 후 예측 작업의 적합도(accuracy)를 측정해 볼게요.
적합도(accuracy)는 분류 모델의 평가 도구 중 하나로 전체 중에 맞춘 비율을 측정하는 도구입니다.
model = LogisticRegression(max_iter=5000)
model.fit(x_train,y_train)
pred_train = model.predict(x_train)
pred_test = model.predict(x_test)
print("학습 데이터 적합도:",accuracy_score(y_train,pred_train))
print("테스트 데이터 적합도:",accuracy_score(y_test,pred_test))[out]학습 데이터 적합도: 0.9821428571428571
테스트 데이터 적합도: 0.9473684210526315분류 모델에서는 predict_proba 메서드를 제공하여 특정 클래스일 확률 값들을 구할 수 있습니다.
pred_testa = model.predict_proba(x_test)
print(y_test[0], np.round(pred_testa[0],4))[out]
0 [0.986 0.014 0. ]결과를 보면 실제 값은 0번 품종(setosa)입니다.
예측 결과를 보면 0번 품종일 확률이 98.6% 1번 품종일 확률이 1.4%, 2번 품종일 확률이 0%로 예측한 것을 알 수 있어요.
선형 회귀 모델을 이용하여 이진 분류기 만들기
이번에는 선형 회귀 모델과 로지스틱 회귀 함수(sigmoid 함수)를 이용하여 직접 이진 분류기를 만들어 봅시다.
만들기 전에 로지스틱 회귀 모델로 이진 분류 작업을 수행해 볼게요. 이 작업은 여기서 만들 이진 분류기로도 똑같이 수행하여 결과를 비교해 볼 거예요.
- 로지스틱 회귀 모델로 이진 분류
먼저 붓꽃 데이터를 로딩하여 data부분은 독립 변수로 종속 변수는 앞에50개는 참, 뒤에 100개는 거짓으로 만들게요.
이는 setosa 품종은 1, 다른 품종은 0으로 정한 것입니다. 따라서 여기서 진행할 이진 분류 작업은 setosa 품종인지 아닌지 판별하는 작업이라 할 수 있습니다.
iris = load_iris()
data = iris.data
target = [1]*50+[0]*100학습 데이터와 테스트 데이터로 분리합시다.
x_train,x_test, y_train,y_test = train_test_split(data,target)로지스틱 모델로 학습 후 적합도를 측정합시다. 여기에서는 학습 데이터와 테스트 데이터의 적합도를 모두 측정할게요.
model = LogisticRegression()
model.fit(x_train,y_train)
pred_train = model.predict(x_train)
pred_test = model.predict(x_test)
print("학습 데이터 적합도:",accuracy_score(y_train,pred_train))
print("테스트 데이터 적합도:",accuracy_score(y_test,pred_test))[out]
학습 데이터 적합도: 1.0
테스트 데이터 적합도: 1.0확률도 예측해 봅시다.
pred_test_proba = model.predict_proba(x_test)
print(y_test[0], np.round(pred_test_proba[0],4))[out]
1 [0.0273 0.9727]결과는 setosa 품종임을 알 수 있습니다.
예측 확률을 보면 setosa 품종이 아닐 확률이 2.73%, setosa 품종일 확률이 97.27%로 나온 것을 알 수 있어요.
- 이진 분류기 만들기
선형 회귀 부분은 LinearRegression 모델을 그대로 사용할게요.
만들 클래스 이름은 BinaryClassifier로 정하기로 할게요.
class BinaryClassifier:
pass생성 과정에서 LinearRegression 모델 개체를 생성하기로 합시다.
여기에서는 LinearRegression 모델과 로지스틱 함수(sigmoid 함수)를 이용한 이진 분류기를 만들어 볼 거예요.
class BinaryClassifier:
def __init__(self):
self.model = LinearRegression()
def sigmoid(self,x):
return 1/(1+np.exp(-x))학습을 수행하는 fit 메서드를 정의합시다.
종속 변수의 값은 0은 -10으로 1은 10으로 변환하기로 할게요.
선형 모델의 결과를 sigmoid 함수에 적용했을 때 가급적 거짓은 0에 가깝고 참은 1에 가깝게 변환할 수 있게 하기 위함입니다.
sigmoid 함수는 음수 무한대를 입력 인자로 받으면 0, 양수 무한대를 입력 인자로 받으면 1에 수렴합니다.
그리고 -10과 10을 입력 인자로 받아도 충분히 0과 1에 근접한 값으로 수렴합니다.
class BinaryClassifier:
def __init__(self):
self.model = LinearRegression()
def sigmoid(self,x):
return 1/(1+np.exp(-x))
def fit(self,x,y):
y = np.array(y)
y = (y*20)-10 #0은 -10, 1은 10으로 변환예측 함수 predict와 예측 확률 함수 predict_proba 메서드를 정의합시다.
예측 함수에서는 선형 회귀 모델로 예측한 결과를 sigmoid 함수로 변환합니다.
이 값이 0.5보다 크거나 같으면 참, 아니면 거짓으로 변환한 후에 이를 정수 값 1, 0으로 변환합니다.
class BinaryClassifier:
def __init__(self):
self.model = LinearRegression()
def sigmoid(self,x):
return 1/(1+np.exp(-x))
def fit(self,x,y):
y = np.array(y)
y = (y*20)-10 #0은 -10, 1은 10으로 변환
self.model.fit(x,y)
def predict(self,x):
re = self.model.predict(x)
return (self.sigmoid(re)>=0.5).astype(int)predict_proba 메서드에서는 선형 모델의 예측 결과를 sigmoid로 변환한 값이 참일 확률, 1- 참일 확률을 거짓일 확률로 만듭니다.
그리고 이 둘을 [거짓 확률, 참 확률] 형태로 묶어서 반환합니다.
class BinaryClassifier:
def __init__(self):
self.model = LinearRegression()
def sigmoid(self,x):
return 1/(1+np.exp(-x))
def fit(self,x,y):
y = np.array(y)
y = (y*20)-10 #0은 -10, 1은 10으로 변환
self.model.fit(x,y)
def predict(self,x):
re = self.model.predict(x)
return (self.sigmoid(re)>=0.5).astype(int)
def predict_proba(self,x):
re1 = self.sigmoid(self.model.predict(x))
re2 = 1- re1
return np.stack([re2,re1],axis=1)이렇게 만든 이진 분류기로 앞에서 수행한 붓꽃 데이터로 setosa 품종이 맞는지 판별하는 이진 분류 작업을 수행해 봅시다.
model = BinaryClassifier()
model.fit(x_train,y_train)
pred_train = model.predict(x_train)
pred_test = model.predict(x_test)
print("학습 데이터 적합도:",accuracy_score(y_train,pred_train))
print("테스트 데이터 적합도:",accuracy_score(y_test,pred_test))[out]
학습 데이터 적합도: 1.0
테스트 데이터 적합도: 1.0결과를 보면 매우 만족할 수 있는 결과를 도출하였습니다.
예측 확률도 확인해 봅시다.
pred_test_proba = model.predict_proba(x_test)
print(y_test[0], np.round(pred_test_proba[0],4))[out]
1 [0.0013 0.9987]결과를 보면 setosa 품종이 맞습니다.
예측 확률은 setosa 품종이 아닐 확률이 0.13%, setosa 품종일 확률은 99.87%로 나왔네요.
실제 LogisticRegression 모델에서는 손실 함수도 mse(mean squared error)가 아닌 binary cross entropy를 사용하지만 이번 실험을 통해 충분히 선형 관계를 sigmoid 함수로 변환한 값으로 이진 분류 문제를 해결할 수있음을 확인하였습니다.
다음은 binary cross entropy 함수를 정의한 예제 코드입니다.
def binary_cross_entropy(pred, y):
return -(pred.log()*y + (1-y)*(1-pred).log()).mean()