
이번에는 수식 파서 트리를 구현하기로 해요.
class Parser
{
수식 파서 트리에서는 어휘 분석기에서 생성한 토큰 컬렉션에 있는 토큰들을 파서 트리에 매달 것입니다. 이에 토큰 컬렉션을 멤버 필드로 선언하세요.
Tokens tokens;
노드를 Parser 클래스 내부에 구조체로 정의합시다. private 가시성 영역이므로 Parser 클래스 외부에서는 노드 구조체 형식을 사용할 수 없어 신뢰성을 높일 수 있어요.
Tokens tokens;
struct Node
{
Token *token;
Node *lc;
Node *rc;
Node(Token *token)
{
this->token = token;
lc = rc = 0;
}
};
루트를 기억할 멤버가 필요하겠죠.
Node *root;
생성자에서는 토큰 컬렉션을 입력 인자로 받습니다.
public:
Parser(Tokens tokens);
~Parser(void); //소멸자
파서 트리에 파싱하는 메서드를 제공합시다.
void Parsing();
후위 표기로 출력하는 메서드도 제공합시다.
void PostOrderView()const;
계산하는 메서드를 제공합시다.
int Calculate();
내부적으로 토큰을 파서 트리에 매다는 메서드가 필요합니다.
private:
void Add(Token *token);
후위 표기로 출력하기 위해 후위 순회하는 메서드가 필요합니다.
void PostOrder(Node *sr)const;
계산할 때도 후위 순회하며 계산합니다.
int PostOrderCalculate(Node *sr);
소멸할 때 동적으로 생성한 모든 노드를 소멸해야겠죠.
void Clear(Node *sr); };
Parser 클래스의 소스 코드를 구현합시다. 먼저 생성자에서는 입력 인자로 받은 컬렉션을 멤버 필드에 설정하세요.
Parser::Parser(Tokens tokens)
{
this->tokens = tokens;
}
소멸자에서는 Clear 메서드를 호출하여 모든 노드를 소멸합니다.
Parser::~Parser(void)
{
Clear(root);
}
모든 노드를 소멸할 때 후위 순회로 소멸해야 합니다.
void Parser::Clear(Node *sr)
{
if(sr)
{
Clear(sr->lc);
Clear(sr->rc);
delete sr;
}
}
파싱하는 메서드를 구현합시다.
void Parser::Parsing()
{
먼저 토큰 개수를 구하세요.
int tcnt = tokens.size();
첫 번째 토큰으로 노드를 생성하여 root에 설정하세요.
root = new Node(tokens[0]);
반복해서 모든 토큰을 파서 트리에 추가하세요.
for(int i = 1; i<tcnt;i++)
{
Add(tokens[i]);
}
}
토큰을 파서 트리에 매다는 메서드를 구현합시다.
void Parser::Add(Token *token)
{
먼저 입력 인자로 받은 토큰을 입력 인자로 노드를 생성하세요.
Node *now = new Node(token);
루트의 토큰을 구하세요.
Token *st = root->token;
루트의 토큰의 우선 순위가 추가할 토큰의 우선 순위보다 크거나 같은지 판별하세요.
if(st->MoreThanPriority(token))
{
예를 들어 추가할 노드의 기호가 더하기나 빼기 기호일 때는 현재 루트에 있는 토큰들은 새로운 노드의 왼쪽 피연산자로 들어가야 합니다. 그리고 루트는 now로 변경해야겠죠.
now->lc = root;
root = now;
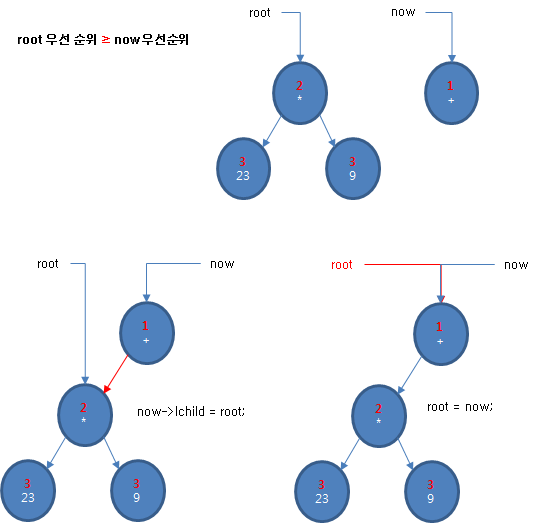
다음은 root의 토큰 우선 순위가 추가할 토큰의 우선 순위보다 크거나 같을 때 링크를 조절하는 과정을 논리적으로 도식한 것입니다.
root의 토큰 우선 순위가 추가할 토큰의 우선 순위보다 작을 때는 새로 추가하는 노드가 피연산자일 때와 연산자일 때 코드가 조금 다릅니다.
else
{
연산자일 때는 새로운 노드의 왼쪽 자식으로 루트의 오른쪽 자식을 매달고 루트의 오른쪽 자식에 새로운 노드를 매답니다.
if(Operand::IsOperand(token)==false)
{
now->lc = root->rc;
root->rc = now;
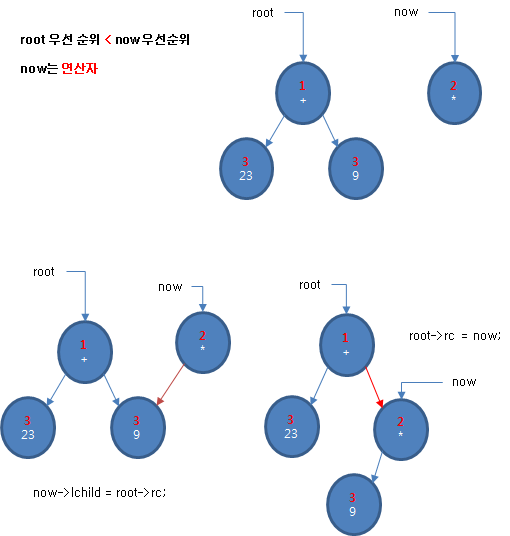
다음은 root의 토큰 우선 순위가 추가할 토큰의 우선 순위보다 작으면서 연산자일 때 링크를 조절하는 과정을 논리적으로 도식한 것입니다.
새로 추가할 토큰이 피연산일 때는 루트에서 오른쪽 자식이 없는 노드를 찾아서 매답니다.
else
{
Node *pa = root;
while(pa->rc)
{
pa = pa->rc;
}
pa->rc = now;
}
}
}
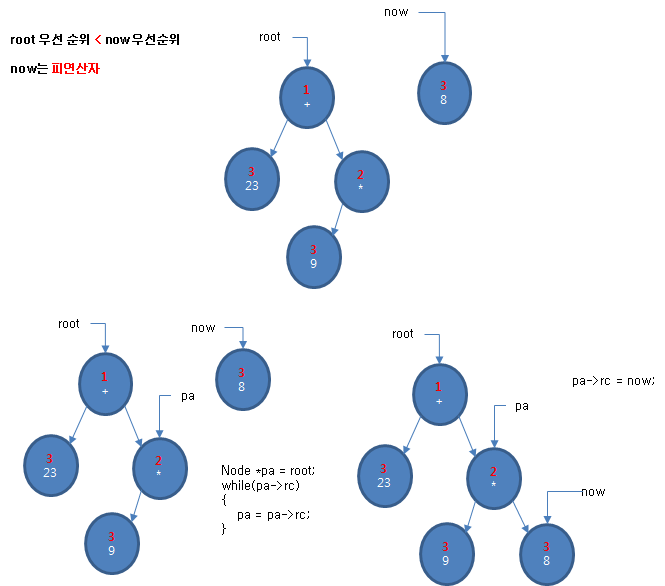
다음은 root의 토큰 우선 순위가 추가할 토큰의 우선 순위보다 작으면서 피연산자일 때 링크를 조절하는 과정을 논리적으로 도식한 것입니다.
후위 순위로 출력하는 메서드를 구현하세요.
void Parser::PostOrderView()const
{
PostOrder(root);
cout<<endl;
}
void Parser::PostOrder(Node *sr)const
{
if(sr)
{
PostOrder(sr->lc);
PostOrder(sr->rc);
sr->token->View();
}
}
계산하여 결과를 반환하는 메서드를 구현하세요.
int Parser::Calculate()
{
return PostOrderCalculate(root);
}
int Parser::PostOrderCalculate(Node *sr)
{
여기에서 구현할 수식 파서 트리에서 모든 노드는 자식이 둘이거나 없습니다. 연산자는 자식이 둘 있고 피연산자는 자식이 없습니다. 따라서 왼쪽 자식이 있다는 것은 연산자를 의미합니다. 먼저 왼쪽 서브 트리를 계산하세요. 그리고 오른쪽 서브 트리를 계산합시다.
if(sr->lc)
{
int lvalue = PostOrderCalculate(sr->lc);
int rvalue = PostOrderCalculate(sr->rc);
현재 토큰을 연산자 토큰으로 변환하세요.
Operator *op = dynamic_cast<Operator *>(sr->token);
그리고 연산 후에 결과를 반환하세요.
return op->Calculate(lvalue, rvalue);
}
피연산자일 때는 값을 반환합니다.
else
{
Operand *op = dynamic_cast<Operand *>(sr->token);
return op->GetValue();
}
}