
수식 계산기는 스택으로 만드는 방법과 파서 트리로 만드는 방법이 있습니다. 정규화를 할 수 있는 구문을 파싱(Parsing)할 때 파서 트리로 구현하면 운행 방법에 따라 원하는 결과물을 얻을 수 있습니다.
이번에는 컴파일러 개념을 도입한 수식 파서 트리를 만들어 보기로 할게요.
파서(Parser)는 파싱하는 도구를 말합니다. 그리고 파싱은 입력 문장을 분석하는 것을 말합니다. 따라서 파서는 입력 문장을 분석하여 원하는 결과물을 만드는 번역기라 할 수 있습니다. 컴파일러도 고급 언어로 작성한 소스를 분석하여 기계어로 번역하므로 내부에 파싱하는 파서가 필요합니다.
컴파일러가 컴파일하는 과정은 여러 단계로 나누며 컴파일러 종류에 따라 다릅니다. 여기에서는 공통적으로 수행해야 하는 과정을 소개하고 이를 수식 파서 트리에 도입해서 구현해 볼게요.
컴파일러는 어휘 분석(Lexical) → 구문 분석(Syntax) → 의미 분석(Semantic) → 파싱(Parsing) → 중간 코드 생성 (Midi Code Generation) 과정을 거칩니다. 컴파일러에 따라 최적화(Optimization) 과정을 거칠 수도 있으며 각 과정을 반복해서 수행하기도 합니다.
어휘 분석(Lexical) 단계는 입력 문장에 의미있는 최소 단위인 토큰(Token)을 만드는 과정으로 토큰 생성기에서 수행합니다. 만약 사용할 수 없는 토큰을 발견하면 오류로 처리합니다. 예를 들어 수식 파서 트리에 입력한 문장 “23-5*9”이 들어오면 “23”, “-“, “5”, “*”, “9”를 토큰으로 만듭니다. “23-5#9”가 들어오면 수식에 사용할 수 없는 “#”가 있어서 오류가 발생합니다.
구문 분석(Syntax)에서는 토큰의 배치가 문법에 맞게 배치하였는지 확인하며 구문 분석기에서 수행합니다. 만약 배치 순서에 문제가 있으면 오류로 처리합니다. 예를 들어 “23-5*9”는 토큰 순서가 수식 문법에 맞습니다. 하지만 “23-5*/7”은 토큰 순서가 수식 문법에 맞지 않아 오류가 발생합니다.
의미 분석(Semantic)에서는 자료 형식이 논리에 맞는지 확인하며 의미 분석기에서 수행합니다. 형식에 맞지 않는 값을 대입하거나 비교하는 부분이 있는지 점검하는 것입니다. 이 책에서 다루는 수식 계산기에서는 의미 분석은 하지 않습니다.
파싱(Parsing)에서는 입력 구문의 각 토큰을 번역 결과물로 만들기 위한 과정으로 파서에서 수행합니다. 파서는 다양한 형태로 표현할 수 있는데 정규화를 할 수 있을 때 파서 트리로 구현하면 효과적입니다. 수식 파서 트리는 운행 방법에 따라 원하는 목적물을 만들 수 있습니다.
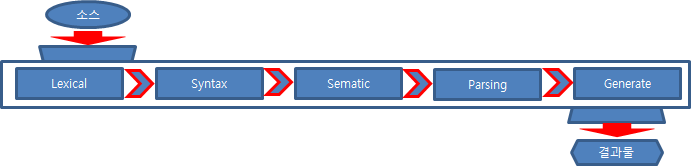
중간 코드 생성(Midi Code Generation)에서는 파싱한 결과물로 목적 파일을 만드는 과정입니다. 여기에서는 수식 파서 트리를 후위 순회하여 계산 결과를 출력하기로 할게요.