
이제 STL의 vector를 모델로 정의한 vector를 구현합시다.
#pragma once
namespace ehlib
{
template<typename Data>
class vector
{
vector에는 자료를 보관하는 저장소를 동적으로 생성하여 자료를 관리합니다. 자료를 보관할 저장소의 위치 정보를 기억할 멤버 필드를 추가하세요.
Data *base;
저장소의 크기를 기억할 멤버를 추가하세요.
size_t bcapacity;
저장소의 크기를 기억할 멤버를 추가하세요.
size_t bcapacity;
보관한 자료 개수를 기억할 멤버를 추가하세요.
size_t bsize;
배열에 보관한 자료를 순차적으로 탐색할 수 있는 반복자를 구현합시다.
public:
class iterator
{
현재 탐색할 위치를 기억할 멤버 필드를 추가하세요.
Data *pos;
생성자를 정의합시다. 반복자에서 가리킬 데이터 정보를 입력 인자로 받게 하며 디폴트 매개변수 값을 0으로 지정하세요.
public:
iterator(Data *pos=0)
{
입력 인자로 전달받은 위치를 멤버 필드에 설정하세요.
this->pos = pos;
}
반복자는 간접 연산을 통해 보관한 개체를 접근할 수 있게 합시다.
Data operator *()const
{
return *pos;
}
보관하거나 삭제할 때 상대적 거리로 저장소에 접근할 필요가 있어요. 이를 위해 -연산을 제공하세요.
int operator-(const iterator &iter)const
{
return pos - iter.pos;
}
전위 증가 연산은 자신을 증가한 뒤에 자신을 반환하세요.
iterator &operator++()
{
pos++;
return (*this);
}
후위 증가 연산은 자신을 복제한 후에 자신의 위치를 증가한 후에 복제한 값을 반환하세요.
const iterator operator++(int)
{
iterator re(*this);
pos++;
return re;
}
비교 연산은 가리키는 위치가 같은지 여부로 판변합니다.
bool operator !=(const iterator &iter)const
{
return pos != iter.pos;
}
bool operator ==(const iterator &iter)const
{
return pos == iter.pos;
}
};
typedef iterator const_iterator;
생성자에서는 저장소가 없는 상태이며 저장소의 크기와 보관 개수가 0인 상태로 설정하세요. 실제 vector는 여기서 구현하는 것보다 훨씬 복잡합니다.
vector()
{
base = 0;
bcapacity = bsize = 0;
}
소멸자에서는 저장소가 유효하면 저장소를 소멸하세요.
~vector()
{
if(base)
{
delete[] base;
}
}
resize 메서드는 첫 번째 인자 개수만큼 vector에 자료를 보관한 상태로 변경하는 메서드입니다. 이미 보관 중인 자료를 제외한 나머지는 두 번째 인자로 전달받은 값으로 설정합니다. 먼저 nsize가 저장소의 크기보다 크면 저장소를 확장하며 이 부분은 별도의 메서드로 정의합시다. 그리고 보관 개수가 nsize가 될 때까지 data를 순차보관하세요.
void resize(size_t nsize,Data data=0)
{
if(nsize>bcapacity)
{
reserve(nsize);
}
while(bsize<nsize)
{
push_back(data);
}
}
저장소의 크기를 배정하는 reserve 메소드를 정의합시다.
void reserve(size_t ncapacity)
{
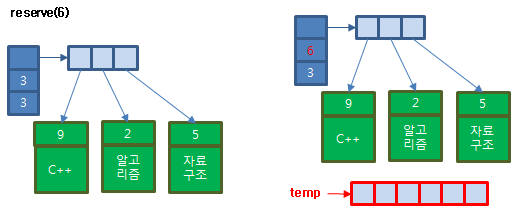
먼저 입력 인자로 전달받은 크기의 저장소를 생성하고 저장소의 크기를 변경하세요.
Data *temp = new Data[ncapacity]; //새로운 저장소를 할당
bcapacity = ncapacity; //새로운 저장소 용량 대입
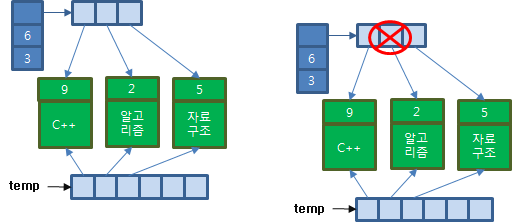
보관한 자료가 있으면 보관한 개수만큼 새로 생성한 버퍼에 복사하고 기존 저장소를 소멸하세요.
if(bsize) //보관한 자료가 있다면
{
for(size_t n=0; n<bsize; n++)
{
temp[n] = base[n]; //기존 저장소에 보관한 자료를 새로운 저장소로 복사
}
delete[] base; //기존 저장소를 소멸
}
base에 새로운 저장소를 대입하세요.
base=temp; //base에 새로운 저장소를 대입
}
순차 보관은 맨 뒤에 보관하는 것입니다. vector에서는 탐색하기 위해 시작 반복자와 끝 반복자를 구하는 메서드를 제공합니다. 여기서 시작 반복자는 저장소의 시작 위치이며 끝 반복자는 마지막 자료를 보관한 다음 위치입니다.
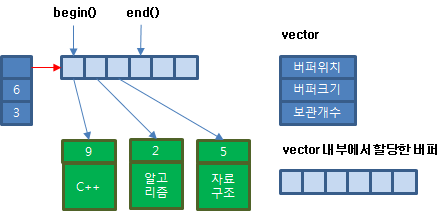
시작 반복자 위치부터 끝 반복자 위치가 나올 때까지 반복하여 탐색하게 작성하였으며 끝 반복자는 탈출 조건을 위해 만든 것입니다. 따라서 끝 반복자는 실제 마지막 자료를 보관한 위치가 아니라 그 다음 위치입니다. 따라서 맨 뒤에 보관하는 것은 end() 앞에 data를 보관하면 되겠죠.
void push_back(Data data)
{
insert(end(),data);
}
특정 위치에 보관하는 insert 메서드를 구현합시다.
꽉 차면 저장소의 크기를 늘려야 합니다. 반복자는 이전 저장소에 자료를 저장한 위치여서 저장소를 확장하면 기존에 위치 정보는 아무런 가치가 없습니다. 따라서 입력 인자로 전달받은 반복자의 위치가 저장소와의 상대적 거리를 계산하세요.
void insert(iterator at, Data data)
{
size_t index = at-base;
if(bsize == bcapacity)
{
//꽉 차면 저장소의 크기를 늘립니다.
//여기에서는 확장할 때 10개의 공간씩 늘리는 것으로 할게요.
reserve(bcapacity+10);
}
//보관할 위치 뒤에 것을 한 칸씩 뒤로 이동해야 합니다.
//뒤쪽부터 이동해야 값의 손실을 막을 수 있어요.
for(size_t pos=bsize; pos>index; pos--)
{
base[pos] = base[pos-1];
}
//저장소의 index 위치에 자료를 보관하고 보관 개수를 1 증가합니다.
base[index] = data;
bsize++;
}
특정 위치에 자료를 지우는 기능입니다. 여기에서 할 일은 보관한 자료의 개수를 1 줄이는 것 뿐만 아니라 지울 위치 뒤에 있는 자료들을 한 칸씩 앞으로 당기는 작업을 수행합니다.
먼저 보관한 자료를 줄이세요. 그리고 입력 인자로 전달받은 반복자의 상대적 위치를 구하세요. 그리고 인덱스가 보관한 자료 개수보다 작으면 인덱스 뒤에 자료를 인덱스 위치에 복사하는 것을 반복하세요.
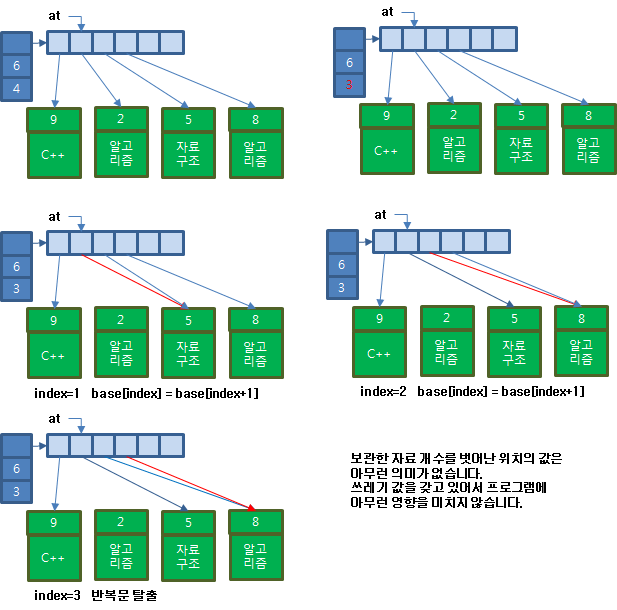
void erase(iterator at)
{
bsize--;
//반복자의 위치가 저장소에서 상대적 거리가 얼마인지 계산한 후에
//뒤쪽 자료를 한 칸씩 앞으로 당기세요.
for(size_t index = at-base; index<bsize; index++)
{
base[index] =base[index+1];
}
}
인덱스 연산을 구현합시다. 인덱스 연산은 대입 연산자 왼쪽에 올 수 있어야 하기 때문에 값을 반환하지 않고 보관한 자료 자체를 반환하기 위해 참조 형식으로 반환하게 정의하였습니다.
Data &operator[] (size_t index)
{
//인덱스가 유효하면 인덱스 위치에 보관한 자료를 반환하세요.
if((index>=0)&&(index<bsize))
{
return base[index];
}
//인덱스가 유효하지 않으면 예외를 던지세요.
//여기에서 0을 반환하는 것은 컴파일 오류입니다.
//반환 형식이 참조 형식임을 주의하세요.
throw "잘못된 인덱스를 사용하였습니다.";
}
상수화 메서드에서 접근할 수 있는 인덱스 연산자도 같은 원리로 구현하세요.
Data &operator[] (size_t index)const
{
if((index>=0)&&(index<bsize))
{
return base[index];
}
throw "잘못된 인덱스를 사용하였습니다.";
}
탐색에 사용할 시작 반복자를 구하는 begin에서는 저장소의 위치를 갖는 반복자를 반환합니다.
iterator begin()
{
iterator iter(base);
return iter;
}
탐색에 사용할 끝 반복자를 구하는 end는 base+bsize를 갖는 반복자를 반환합니다. 끝 반복자는 탐색 반복문에서 탈출 조건으로 사용할 것이므로 맨 뒤에 보관한 다음 위치를 반환하는 것입니다.
iterator end()
{
iterator iter(base+bsize);
return iter;
}
상수화 메서드에서 사용하기 위한 메서드도 구현은 같습니다.
const_iterator begin()const
{
iterator iter(base);
return iter;
}
const_iterator end()const
{
iterator iter(base+bsize);
return iter;
}
보관한 원소 개수를 구하는 기능을 구현하세요.
size_t size()
{
return bsize;
}
저장소의 크기를 구하는 기능을 구현하세요.
size_t capacity()
{
return bcapacity;
}
};
}
이번에는 find_if 알고리즘을 구현합시다.
namespace ehlib
{
template <typename Iter,typename Fun>
Iter find_if(Iter beg,Iter end,Fun fun)
{
//find_if는 탐색 구간을 순차적으로 이동하면서
//원하는 조건을 만족하는 위치를 찾는 알고리즘입니다.
for( ;beg != end ; ++beg)
{
//세 번째 전달할 함수(혹은 함수 개체)에
//탐색 구간에 있는 자료를 적용했을 때 참인지 판별합니다.
//반복자는 간접 연산으로 보관한 자료를 구할 수 있으니 다음처럼 표현할 수 있어요.
if(fun(*beg))
{
break;
}
}
return beg;
}
}
이제 3장에서 STL에서 제공하는 vector를 사용했던 프로그램에서 여기서 만든 vector와 find_if를 사용하게 헤더 파일 포함문과 using 문을 변경하여 테스트 해 보세요.
이처럼 내부를 파헤치는 작업을 internal이라 부릅니다. 보통 internal 작업은 만드는 것이 목적이 아니라 내부를 이해하기 위한 것입니다. 지금처럼 비슷하게 구현할 수도 있지 논리적으로 분석할 수도 있겠죠.