힙 정렬은 힙 트리를 이용하는 알고리즘입니다. 최대 힙을 사용하면 크기 순(Ascend)으로 정렬하고 최소 힙을 사용하면 크기 역순(Descend)으로 정렬합니다.
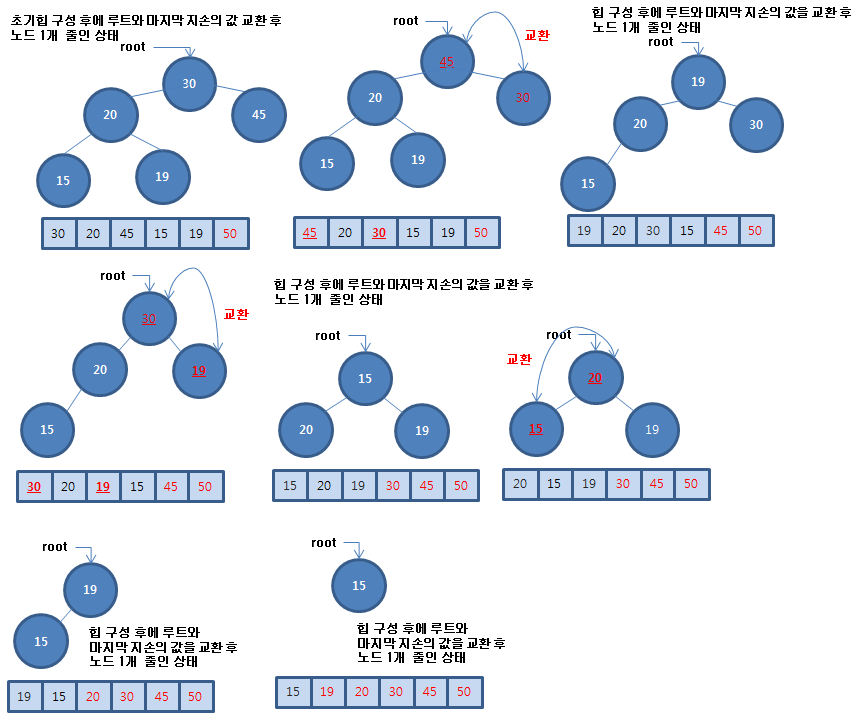
힙 정렬은 먼저 힙 트리를 구성합니다. 그리고 루트의 값과 맨 마지막 값을 교환한 후에 정렬 범위를 1 줄입니다. 이와 같은 작업을 반복하여 정렬 범위가 1일 때까지 반복합니다.
최대 힙 트리에서 루트는 최대 값을 갖습니다. 따라서 마지막 값과 교환하면 제일 큰 값이 맨 뒤로 배치할 수 있습니다. 그리고 난 후에 정렬 범위를 줄여나가면 최종적으로 정렬 상태를 만들 수 있는 것입니다.
힙 정렬(base:배열의 시작 주소, n: 원소 개수, compare:비교 논리)
초기 힙 구성
루트와 맨 마지막 자손 교환
n을 1 감소
반복(n: n->1)
힙 구성
루트와 맨 마지막 자손 교환
n을 1 감소
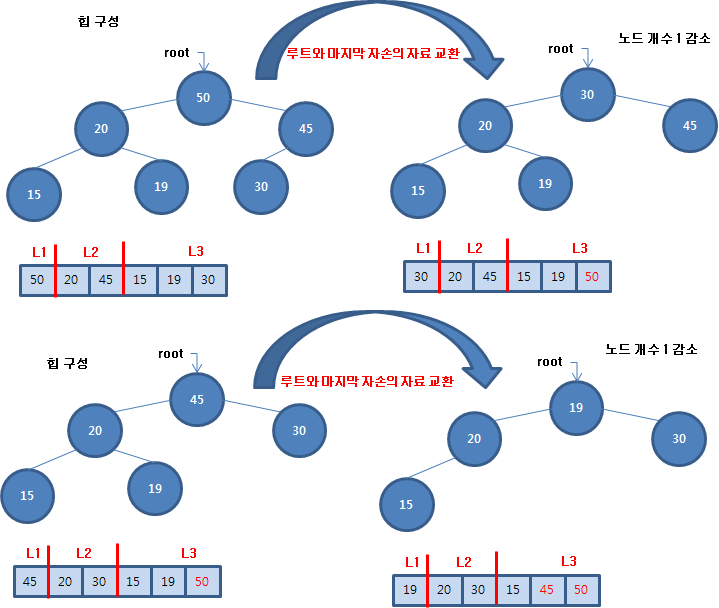
힙을 구성하는 방법은 초기에 힙을 구성하는 방법과 루트와 마지막 자식을 교환한 후에 루트에 있는 자료를 힙 트리 논리에 맞는 자리를 찾는 방법이 있습니다.
먼저 초기에 힙을 구성하는 방법을 순차적으로 힙 트리에 추가하는 과정으로 진행합니다. 새로 추가하는 노드는 부모와 크기를 비교하여 추가할 자료의 값이 더 크면 부모와 자료를 교환해 나갑니다. 만약 부모가 더 크면 자리를 찾은 것입니다.
이를 의사코드로 표현하면 다음과 같습니다.
초기 힙 구성(base:배열의 시작 주소, n: 원소 개수, compare:비교 논리)
반복(i:1->n)
j:=1
반복(j>0)
pa:=PARENT(j)
조건: compare(base[j], base[pa])이 0보다 크면
base[j], base[pa] 교환
j: = pa
아니면
내부 루프 탈출
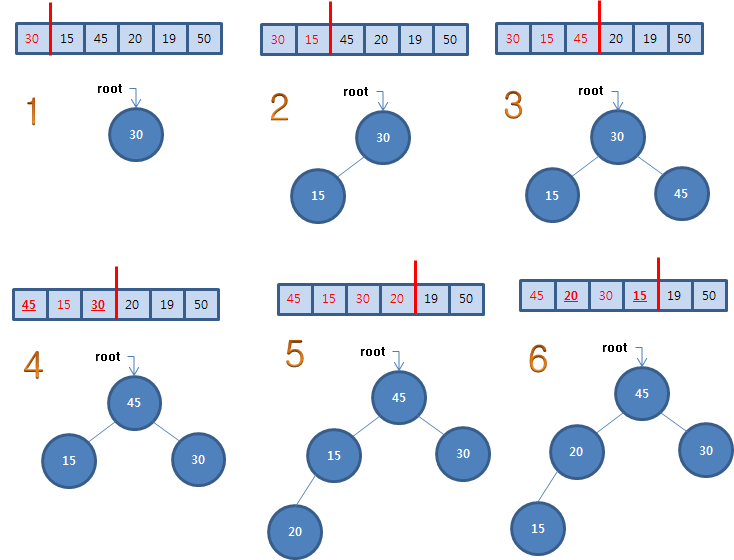
루트와 마지막 자손 노드의 자료를 교환한 후에 노드 개수를 1 감소한 후에 루트에 있는 자료를 배치하는 것은 자식들 값 중에 큰 값과 비교하여 자신의 값이 작을 때 교환해 나가는 것을 반복합니다. 만약 자식이 없거나 자신이 자식들 값보다 크거나 같으면 작업은 끝납니다. 자식이 없거나 자식이 왼쪽만 있을 수 있으며 이를 고려한 의사 코드는 다음과 같습니다.
힙 구성(base:배열의 시작 주소, n: 원소 개수, compare:비교 논리)
반복
lc:= LCHILD(me)
rc:= RCHILD(me)
자식이 없으면
탈출
조건 왼쪽 자식만 있을 때
조건 compare(base[me],base[lc])>0일 때
base[me], base[lc] 교환
탈출
bc := 왼쪽 자식과 오른쪽 자식 중에 자료가 큰 값의 인덱스
조건 compare(base[bc],base[me])>0일 때
base[bc],base[me] 교환
아니면
탈출