
안녕하세요. 언제나 휴일에 언휴예요.
이번 강의는 R에서 기본적으로 제공하는 입출력을 살펴볼게요.
기본 출력: print, cat, writeLines, write.table, write.csv, save
기본 입력: scan, edit, readLines, read.table, read.csv, load
입출력은 서로 대응하는 것들이 있습니다.
별도의 함수로 설명하는 부분과 대응하는 것을 같이 설명하는 형태를 섞어서 강의할게요.
print(x,…)
가장 간단하게 출력하는 함수입니다.
첫 번째 인자로 출력할 표현을 전달합니다.
두 번째 인자부터는 출력 포멧이나 폭, 정렬 등을 다루는데 별도의 글로 게시할게요.
첫 번째 인자로 값이나 변수 모두 표현 가능합니다.
다음은 “hello” 표현과 변수 x 표현을 입력 인자로 출력한 예입니다.
> #print
> print("hello")
[1] "hello"
> x=c(1,2,3)
> print(x)
[1] 1 2 3
cat
cat(…,file=””,sep=””,fill=FALSE, labels=NULL,append=FALSE)
cat은 여러 개의 인자를 출력하는 것이 가능합니다.
sep=’구분자’를 통해 출력할 원소 사이에 구분자를 출력하는 것도 가능합니다.
또한 출력할 인자 뒤에 file=”파일명”을 전달하면 특정 파일에 저장하는 것도 가능합니다.
주의할 점은 파일에 저장할 때 개행 문자를 자동으로 추가하지 않습니다. 이는 readLines 함수 등으로 읽어올 때 에러를 유발할 수 있습니다.
되도록이면 파일에 데이터를 기록할 때 개행을 추가하는 습관을 가져주세요.(바이너리 입출력 제외)
> #cat
> cat("hello")
hello
> cat(x)
1 2 3
> cat("hello",x)
hello 1 2 3
> cat("hello",x,seq='-')
hello 1 2 3 -
> cat("hello",x,seq='\n')
hello 1 2 3
> cat("hello",x,seq='\n',file='data.txt')
> cat("hello",file="data2.txt")
> readLines("data2.txt")
[1] "hello"
경고메시지(들):
In readLines("data2.txt") :
'data2.txt'에서 불완전한 마지막 행이 발견되었습니다
writeLines , readLines
writeLines(text, con = stdout(), sep = “\n”, useBytes = FALSE)
readLines(con = stdin(), n = -1L, ok = TRUE, warn = TRUE, encoding = “unknown”, skipNul = FALSE)
writeLines는 문장을 출력할 때 사용합니다.
text는 character vector이어서 numerice이나 logical 등을 출력할 때 사용할 수 없습니다.
출력을 연결할 스트림을 전달하지 않으면 기본 출력이며 명시하여 파일에 출력할 수 있습니다.
readLine은 읽어올 때 사용합니다.
> #writeLines
> writeLines(c(1,2,3))
Error in writeLines(c(1, 2, 3)) :
오로지 문자형 객체들을 기록할 수만 있습니다
> writeLines("Hello")
Hello
> writeLines("Hello","data3.txt")
> readLines("data3.txt")
[1] "Hello"
write.table, read.table
write.table(x, file = “”, 생략)
read.table(file, header = FALSE, sep = “”, quote = “\”‘”, 생략)
write.table 이름에서 풍기는 것처럼 data.frame이나 matrix를 출력하는 것이 가능합니다.
read.table 또한 읽어 오는 것이 가능합니다.
> #write.table
> n=c(12,34,50)
> na=c("홍길동","강감찬","을지문덕")
> mt = data.frame("번호"=n,"이름"=na)
> write.table(mt,file="data4.txt")
> mt2=read.table("data4.txt")
> mt
번호 이름
1 12 홍길동
2 34 강감찬
3 50 을지문덕
> mt2
번호 이름
1 12 홍길동
2 34 강감찬
3 50 을지문덕
write.csv, read.csv
write.csv(…)
read.csv(file, header = TRUE, sep = “,”, quote = “\””,dec = “.”, fill = TRUE, comment.char = “”, …)
csv 파일에 기록하거나 읽을 때 사용합니다.
주의할 점은 data.frame을 기록할 때 row.names=FALSE로 지정하여 출력할 것인지 등을 고민해야 할 것입니다.
다음 예제에서는 row.names=FALSE를 지정하여 출력하는 것과 지정하지 않았을 때의 차이점을 보여줍니다.
> #write.csv
> write.csv(mt,file="data.csv")
> mt3=read.csv("data.csv")
> mt3
X 번호 이름
1 1 12 홍길동
2 2 34 강감찬
3 3 50 을지문덕
> write.csv(mt,file="data2.csv",row.names =FALSE)
> mt4=read.csv("data2.csv")
> mt4
번호 이름
1 12 홍길동
2 34 강감찬
3 50 을지문덕
> mt
번호 이름
1 12 홍길동
2 34 강감찬
3 50 을지문덕
scan
scan(file=””,생략)
콘솔이나 파일에서 vector나 list 입력에 사용합니다.
아무 입력 없이 엔터를 전달할 때까지 내용을 입력 데이터로 취급합니다.
> #scan > x=scan() 1: 12 2: 23 3: 34 4: Read 3 items > x [1] 12 23 34
edit
edit(name = NULL, file = “”, title = NULL,editor = getOption(“editor”), …)
텍스트 편집기를 실행시켜 입력할 수 있게 합니다.
다음은 벡터와 data.frame을 입력 인자로 전달하여 edit을 호출하였을 때의 화면입니다.
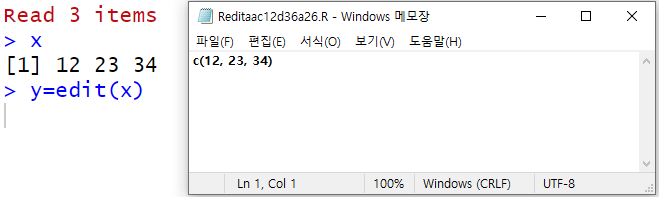
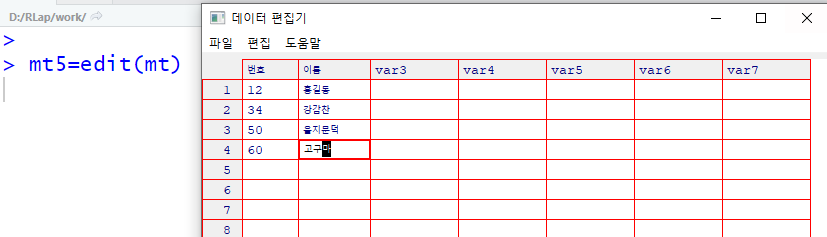
#edit > mt5=edit(mt) > mt5 번호 이름 1 12 홍길동 2 34 강감찬 3 50 을지문덕 4 60 고구마 > y=edit(x) > y [1] 45 33 67 > mt5=edit(mt) > mt5 번호 이름 1 12 홍길동 2 34 강감찬 3 50 을지문덕 4 60 고구마
save, load
save(…,생략)
load(file, envir = parent.frame(), verbose = FALSE)
save는 바이너리로 객체 정보를 기록합니다. 이는 변수가 참조하는 객체를 직렬화하여 기록하는 것을 말합니다.
load는 바이너리에서 로딩하여 객체화합니다. 이는 역직렬화하여 객체를 생성하는 것을 말합니다.
다음은 mt를 save로 기록한 후에 rm명령으로 mt를 제거합니다. 그리고 다시 load로 읽어와서 mt 변수를 확인하면 객체가 살아난 것을 알 수 있습니다.
> save(mt,file="r.RData")
> rm(mt)
> mt
에러: 객체 'mt'를 찾을 수 없습니다
> load("r.RData")
> mt
번호 이름
1 12 홍길동
2 34 강감찬
3 50 을지문덕
객체냐 개체냐?
*object를 번역할 때 개체 혹은 객체로 번역합니다. Microsoft 사의 기술을 다룰 때는 개체라는 용어를 사용하며 R언어에서는 객체를 사용합니다. 언제나 휴일에서는 개체를 주로 사용하나 R언어에서는 객체라는 용어를 사용합니다.*