
안녕하세요. 언제나 휴일에 언휴입니다.
기계 학습을 시작할 때 많은 개발자들은 사이킷 런(scikit-learn) 라이브러리를 사용합니다.
이번 강의는 사이킷 런을 사용하는 출발점인 svm.SVC 객체의 fit 메서드와 predict 메서드를 사용해 볼 거예요. 그리고 내부를 좀 더 이해하기 위해 비슷하게 동작하는 클래스를 만들어 봅시다.
== 다루는 내용 == 사이킷 런의 svm.SVC 사용 흉내내기 - TinySVC 클래스 외형 정의 초기화 메서드 정의 가중치와 임계치 설정 메서드 정의 판별 메서드 정의 특정 가중치와 임계치 테스트 메서드 정의 기계 학습 메서드 정의 fit 메서드 정의 predict 메서드 정의 전체 코드
사이킷 런의 svm.SVC 사용
이번 실습에서는 OR 연산을 입력 데이터와 결과로 사용할 거예요.
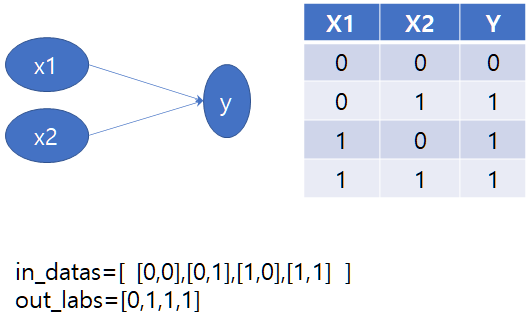
사이킷 런에 svm을 사용하기 위해 import문을 표현합니다.
from sklearn import svm
svm.SVC 객체를 생성합니다.
clf = svm.SVC()
svc.SVC 객체의 fit 메서드를 호출하여 입력 데이터와 출력 결과를 설정합니다.
svm.SVC 객체 내부에서는 이를 바탕으로 기계 학습을 수행합니다. 퍼셉트론 알고리즘을 예로 들면 가중치와 임계치를 구한다고 볼 수 있어요.
clf.fit(in_datas, out_labs) #퍼셉트론 구하기 - 가중치와 임계치를 구한다.
이제 predict 메서드를 호출하여 알고 싶은 입력 데이터를 전달하면 기계 학습 결과를 알 수 있어요.
results = clf.predict(examples) #예측
다음은 사이킷 런의 svm.SVC를 사용하는 예제 코드입니다.
from sklearn import svm in_datas = [[0,0],[0,1],[1,0],[1,1]] out_labs = [0,1,1,1] examples = [[0,1],[1,0]] clf = svm.SVC() clf.fit(in_datas, out_labs) #퍼셉트론 구하기 - 가중치와 임계치를 구한다 results = clf.predict(examples) #결과 예측 print(results)
흉내내기 – TinySVC 클래스 외형 정의
이제 사용한 코드에 svm.SVC 대신 우리가 만들 TinySVC 클래스로 바꿀게요.
class TinySVC:
def fit(self,datas,labels):
print('fit')
def predict(self,samples):
print('predict')
in_datas = [[0,0],[0,1],[1,0],[1,1]]
out_labs = [0,1,1,1]
examples = [[0,1],[1,0]]
clf = TinySVC()
clf.fit(in_datas, out_labs) #퍼셉트론 구하기 - 가중치와 임계치를 구한다
results = clf.predict(examples) #결과 예측
print(results)
초기화 메서드 정의
입력 데이터와 결과 데이터를 기억하는 멤버가 필요합니다.
TinySVC는 두 개의 입력 인자의 가중치와 임계치를 결정하는 흉내내기 클래스입니다.
이를 위해 두 개의 입력 인자의 가중치와 임계치를 위한 멤버도 선언합니다.
class TinySVC:
def __init__(self):
self.datas,self.labels=[],[]
self.w1,self.w2,self.b=0,0,0
가중치와 임계치 설정 메서드 정의
가중치와 임계치를 설정하는 메서드도 정의합시다.
class TinySVC:
def __setwb(self,w1,w2,b):
self.w1,self.w2,self.b = w1,w2,b
판별 메서드 정의
입력 데이터를 받아 가중치와 임계치를 적용하여 판별하는 메서드를 정의합시다.
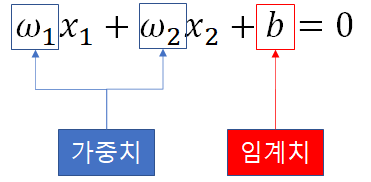
class TinySVC:
def __discriminate(self,x1,x2):
if(self.w1*x1+self.w2*x2+self.b<=0):
return 0
else:
return 1
특정 가중치와 임계치 테스트 메서드 정의
특정 가중치와 임계치가 맞는지 테스트하는 메서드를 정의합시다.
먼저 가중치와 입계치를 설정합니다.
그리고 결과의 개수만큼 반복해서 판별 메서드를 호출합니다.
한 번 이라도 판별 결과가 거짓이면 가중치와 임계치는 잘못된 값입니다.
*품질 수준을 높이기 위해 오차 를 계산할 수 있을 거예요. 여기에서는 생략합니다. *
class TinySVC:
def __test(self,wt1,wt2,bt):
self.__setwb(wt1,wt2,bt)
for r in range(len(self.labels)):
if(self.__discriminate(self.datas[r][0],self.datas[r][1])!=self.labels[r]):
return False
return True
기계 학습 메서드 정의
다양한 가중치와 임계치로 테스트하는 기계 학습 메서드를 정의합시다.
여기에서는 svm.SVC를 흉내내고 각 메서드를 이해하기 위함입니다.
시원치 않은 기계 학습 메서드를 정의할 것이므로 여러분의 기대는 안드로메다로 보낼게요.
x1의 가중치를 0%에서 100%까지 10% 단위로 증가하면 테스트할게요.
x2의 가중치를 0%에서 100%까지 10% 단위로 증가하면 테스트할게요.
임계치는 -1에서 1로 0.1씩 증가하면서 테스트할게요.
참고로 이러한 기계 학습은 말도 안되는 것입니다. OR 연산을 예로 들었기에 가능한 것입니다.
임계치 테스트 범위를 넓히면 선형 퍼셉트론은 어느 정도 가능하지만 효율이 떨어지는 것은 여전하며 품질 수준은 극악한 수준입니다.
def myr(s,e,st): #range와 같은 목적, step이 실수
r=s
while(r<e):
yield r
r+=st
class TinySVC:
def __findwb(self):
for wt1 in myr(0,1,0.1):
for wt2 in myr(0,1,0.1):
for bt in myr(-1,1,0.1):
if(self.__test(wt1,wt2,bt)):
return True
return False
fit 메서드 정의
이제 fit 메서드를 정의할 차례입니다.
입력 데이터와 결과 데이터를 설정합니다.
그리고 기계 학습 메서드를 호출합니다.
class TinySVC:
def fit(self,datas,labels):
self.datas,self.labels = datas,labels
self.__findwb()
predict 메서드 정의
마지막으로 predict 메서드를 정의합시다.
입력인자로 들어온 샘플들을 판별 메서드를 이용하여 결과를 얻어냅니다.
그리고 결과 리스트를 반환합니다.
class TinySVC:
def predict(self,samples):
result=[]
for sample in samples:
result.append(self.__discriminate(sample[0],sample[1]))
return result
전체 코드
다음은 이번 실습에서 정의한 전체 코드입니다.
# https://ehpub.co.kr
# ML with pYTHON
# 사이킷 런의 svm.svc 내부 - 흉내내기
# svc 클래스, svc.fit 메서드, svc.predict 메서드
def myr(s,e,st): #range와 같은 목적, step이 실수
r=s
while(r<e):
yield r
r+=st
class TinySVC:
def __init__(self): #초기화
self.datas,self.labels=[],[]
self.w1,self.w2,self.b=0,0,0
def __setwb(self,w1,w2,b): #가중치, 임계치 설정
self.w1,self.w2,self.b = w1,w2,b
def __discriminate(self,x1,x2): #판별
if(self.w1*x1+self.w2*x2+self.b<=0):
return 0
else:
return 1
def __test(self,wt1,wt2,bt): #특정 가중치, 임계치 테스트
self.__setwb(wt1,wt2,bt)
for r in range(len(self.labels)):
if(self.__discriminate(self.datas[r][0],self.datas[r][1])!=self.labels[r]):
return False
return True
def __findwb(self): #기계 학습 - 극악한 품질 수준
for wt1 in myr(0,1,0.1):
for wt2 in myr(0,1,0.1):
for bt in myr(-1,1,0.1):
if(self.__test(wt1,wt2,bt)):
return True
return False
def fit(self,datas,labels):
self.datas,self.labels = datas,labels
self.__findwb()
def predict(self,samples):
result=[]
for sample in samples:
result.append(self.__discriminate(sample[0],sample[1]))
return result
in_datas = [[0,0],[0,1],[1,0],[1,1]]
out_labs = [0,1,1,1]
examples = [[0,1],[1,0]]
clf = TinySVC()
clf.fit(in_datas, out_labs) #퍼셉트론 구하기 - 가중치와 임계치를 구한다
results = clf.predict(examples) #결과 예측
print(results)